1
/
5
Pomen normalne porazdelitve na številnih področjih znanosti (na primer v matematični statistiki in statistični fiziki) izhaja iz osrednjega mejnega izreka teorije verjetnosti. Če je rezultat opazovanja vsota številnih naključnih, šibko medsebojno odvisnih spremenljivk, od katerih vsaka prispeva majhen prispevek glede na skupno vsoto, potem ko se število izrazov povečuje, se porazdelitev osredotočenega in normaliziranega rezultata nagiba k normalni. Ta zakon teorije verjetnosti ima za posledico široko razširjenost normalne porazdelitve, kar je bil eden od razlogov za njegovo ime.
Lastnosti
Trenutki
Če so naključne spremenljivke X 1 (\displaystyle X_(1)) in X 2 (\displaystyle X_(2)) so neodvisne in imajo normalno porazdelitev z matematičnimi pričakovanji μ 1 (\displaystyle \mu _(1)) in μ 2 (\displaystyle \mu _(2)) in disperzije σ 1 2 (\displaystyle \sigma _(1)^(2)) in σ 2 2 (\displaystyle \sigma _(2)^(2)) oziroma potem X 1 + X 2 (\displaystyle X_(1)+X_(2)) ima tudi normalno porazdelitev s pričakovano vrednostjo μ 1 + μ 2 (\displaystyle \mu _(1)+\mu _(2)) in disperzija σ 1 2 + σ 2 2 . (\displaystyle \sigma _(1)^(2)+\sigma _(2)^(2).) To pomeni, da lahko normalno naključno spremenljivko predstavimo kot vsoto poljubnega števila neodvisnih normalnih naključnih spremenljivk.
Največja entropija
Normalna porazdelitev ima največjo diferencialno entropijo med vsemi zveznimi porazdelitvami, katerih varianca ne presega dane vrednosti.
Modeliranje normalnih psevdo-naključnih spremenljivk
Najenostavnejše približne metode modeliranja temeljijo na osrednjem mejnem izreku. Namreč, če dodamo več neodvisnih enako porazdeljenih količin s končno varianco , potem bo vsota porazdeljena približno V redu. Na primer, če dodate 100 neodvisnih standardov enakomerno porazdeljene naključne spremenljivke, potem bo porazdelitev vsote približno normalno.
Za generiranje programske opreme normalno porazdeljenih psevdonaključnih spremenljivk je bolje uporabiti transformacijo Box - Muller. Omogoča vam, da ustvarite eno normalno porazdeljeno vrednost na podlagi ene enakomerno porazdeljene vrednosti.
Normalna porazdelitev v naravi in aplikacijah
Normalno porazdelitev pogosto najdemo v naravi. Na primer, naslednje naključne spremenljivke so dobro modelirane z normalno porazdelitvijo:
- odklon streljanja.
- merilne napake (vendar imajo napake nekaterih merilnih instrumentov nenormalne porazdelitve).
- nekatere značilnosti živih organizmov v populaciji.
Ta porazdelitev je tako razširjena, ker je neskončno deljiva neprekinjena porazdelitev s končno varianco. Zato se mu nekateri drugi približujejo v mejah, na primer binom in Poisson. S to distribucijo je modeliranih veliko nedeterminističnih fizikalnih procesov.
Povezava z drugimi distribucijami
- Normalna porazdelitev je Pearsonova porazdelitev tipa XI.
- Razmerje para neodvisnih standardnih normalno porazdeljenih naključnih spremenljivk ima Cauchyjevo porazdelitev. Se pravi, če je naključna spremenljivka X (\displaystyle X) predstavlja razmerje X = Y / Z (\displaystyle X=Y/Z)(kje Y (\displaystyle Y) in Z (\displaystyle Z) so neodvisne standardne normalne naključne spremenljivke), potem bo imela Cauchyjevo porazdelitev.
- Če z 1 , … , z k (\displaystyle z_(1),\ldots,z_(k)) so skupaj neodvisne standardne normalne naključne spremenljivke, t.j. z i ∼ N (0 , 1) (\displaystyle z_(i)\sim N\left(0,1\desno)), nato naključna spremenljivka x = z 1 2 + … + z k 2 (\displaystyle x=z_(1)^(2)+\ldots +z_(k)^(2)) ima hi-kvadrat porazdelitev s k stopnjami svobode.
- Če je naključna spremenljivka X (\displaystyle X) je predmet lognormalne porazdelitve, potem ima njen naravni logaritem normalno porazdelitev. Se pravi, če X ∼ L o g N (μ , σ 2) (\displaystyle X\sim \mathrm (LogN) \left(\mu,\sigma ^(2)\desno)), potem Y = ln (X) ∼ N (μ , σ 2) (\displaystyle Y=\ln \left(X\right)\sim \mathrm (N) \left(\mu ,\sigma ^(2)\right )). In obratno, če Y ∼ N (μ , σ 2) (\displaystyle Y\sim \mathrm (N) \left(\mu,\sigma ^(2)\desno)), potem X = exp (Y) ∼ L o g N (μ , σ 2) (\displaystyle X=\exp \left(Y\right)\sim \mathrm (LogN) \left(\mu,\sigma ^(2) \prav)).
- Razmerje kvadratov dveh standardnih normalnih naključnih spremenljivk ima
Zakon normalne porazdelitve (pogosto imenovan Gaussov zakon) ima v teoriji verjetnosti izjemno pomembno vlogo in zavzema posebno mesto med drugimi zakoni distribucije. To je najpogostejši zakon o distribuciji v praksi. Glavna značilnost, po kateri se normalni zakon razlikuje od drugih zakonov, je, da je omejevalni zakon, h kateremu se drugi zakoni distribucije približujejo pod zelo pogosto značilnimi pogoji.
Dokaže se lahko, da vsota dovolj velikega števila neodvisnih (ali šibko odvisnih) naključnih spremenljivk, za katere veljajo poljubni zakoni distribucije (ob upoštevanju nekaterih zelo ohlapnih omejitev), približno ustreza normalnemu zakonu, in to drži, bolj natančno, čim večja je število naključnih spremenljivk se sešteje. Večino naključnih spremenljivk, ki jih srečamo v praksi, kot so na primer meritvene napake, napake pri streljanju ipd., lahko predstavimo kot vsoto zelo velikega števila razmeroma majhnih členov – elementarnih napak, od katerih je vsaka posledica delovanje ločenega vzroka, ki ni odvisen od drugih. Ne glede na to, kateri zakoni porazdelitve so lahko podvrženi posameznim elementarnim napakam, se značilnosti teh porazdelitev v vsoti velikega števila izrazov izravnajo in izkaže se, da je vsota podvržena zakonu, ki je blizu normalnemu. Glavna omejitev, ki velja za seštevne napake, je, da imajo vse enako majhno vlogo v skupni vsoti. Če ta pogoj ni izpolnjen in se na primer izkaže, da ena od naključnih napak močno prevladuje nad vsemi drugimi po svojem vplivu na vsoto, potem bo zakon porazdelitve te prevladujoče napake naložil svoj vpliv na vsoto in določil v svojih glavnih značilnostih zakon o distribuciji.
Izreke, ki določajo normalni zakon kot mejo za vsoto neodvisnih enakomerno majhnih naključnih členov, bomo podrobneje obravnavali v 13. poglavju.
Za normalni zakon porazdelitve je značilna gostota verjetnosti v obliki:
Krivulja porazdelitve po normalnem zakonu ima simetričen hribovit videz (slika 6.1.1). Največja ordinata krivulje, enaka , ustreza točki ; ko se odmikamo od točke, se gostota porazdelitve zmanjšuje in pri , se krivulja asimptotično približuje osi abscise.

Ugotovimo pomen numeričnih parametrov in vključenih v izraz normalnega zakona (6.1.1); dokazali bomo, da vrednost ni nič drugega kot matematično pričakovanje, vrednost pa je standardni odklon vrednosti. Da bi to naredili, izračunamo glavne številčne značilnosti količine - matematično pričakovanje in varianco.

Uporaba spremembe spremenljivke
Preprosto je preveriti, da je prvi od dveh intervalov v formuli (6.1.2) enak nič; drugi je dobro znani Euler-Poissonov integral:
 . (6.1.3)
. (6.1.3)
zato
tiste. parameter je matematično pričakovanje vrednosti. Ta parameter, zlasti pri strelskih nalogah, se pogosto imenuje središče razpršitve (skrajšano kot c.r.).
Izračunajmo disperzijo količine:
 .
.
Ponovno uveljavitev spremembe spremenljivke
Z integracijo po delih dobimo:
Prvi člen v zavitih oklepajih je enak nič (saj ko pada hitreje, kot se poveča katera koli moč), je drugi člen po formuli (6.1.3) enak , od koder
Zato parameter v formuli (6.1.1) ni nič drugega kot standardni odmik vrednosti.
Ugotovimo pomen parametrov in normalno porazdelitev. Neposredno iz formule (6.1.1) je razvidno, da je središče simetrije porazdelitve središče sipanja. To je jasno iz dejstva, da se izraz (6.1.1) ne spremeni, ko je predznak razlike obrnjen. Če spremenite disperzijsko središče, se bo krivulja porazdelitve premaknila vzdolž osi x, ne da bi spremenila svojo obliko (slika 6.1.2). Središče sipanja označuje položaj porazdelitve na osi x.

Dimenzija središča sipanja je enaka dimenziji naključne spremenljivke.
Parameter ne označuje položaja, temveč samo obliko porazdelitvene krivulje. To je značilnost disperzije. Največja ordinata porazdelitvene krivulje je obratno sorazmerna z ; pri naraščanju se maksimalna ordinata zmanjša. Ker mora površina porazdelitvene krivulje vedno ostati enaka enoti, ko se krivulja porazdelitve povečuje, postane bolj ravna in se razteza vzdolž osi x; nasprotno, z zmanjšanjem se krivulja porazdelitve razteza navzgor, hkrati pa se skrči s strani in postane bolj igličasta. Na sl. 6.1.3 prikazuje tri normalne krivulje (I, II, III) pri ; od teh krivulja I ustreza največji vrednosti, krivulja III pa najmanjši vrednosti. Sprememba parametra je enakovredna spreminjanju merila porazdelitvene krivulje – povečanje lestvice vzdolž ene osi in enako zmanjšanje vzdolž druge.
Primeri naključnih spremenljivk, porazdeljenih po normalnem zakonu, so višina osebe, masa ulovljenih rib iste vrste. Normalna porazdelitev pomeni naslednje
: obstajajo vrednosti človeške višine, mase rib iste vrste, ki so intuitivno zaznane kot "normalne" (in dejansko - povprečne) in so v dovolj velikem vzorcu veliko pogostejše kot tiste ki se razlikujejo navzgor ali navzdol.
Normalno porazdelitev verjetnosti neprekinjene naključne spremenljivke (včasih Gaussova porazdelitev) lahko imenujemo zvonasta zaradi dejstva, da je gostotna funkcija te porazdelitve, ki je simetrična glede na povprečje, zelo podobna rezu zvona ( rdeča krivulja na zgornji sliki).
Verjetnost izpolnjevanja določenih vrednosti v vzorcu je enaka površini figure pod krivuljo, v primeru normalne porazdelitve pa vidimo, da je pod vrhom "zvona" , kar ustreza vrednostim, ki se nagibajo k povprečju, je površina in s tem verjetnost večja kot pod robovi. Tako dobimo isto stvar, kot je bilo že rečeno: verjetnost, da srečamo osebo "normalne" višine, ulovimo ribo "normalne" teže, je večja kot pri vrednostih, ki se razlikujejo navzgor ali navzdol. V zelo številnih primerih v praksi so merilne napake porazdeljene v skladu z zakonom, ki je blizu normalnemu.
Ustavimo se spet pri sliki na začetku lekcije, ki prikazuje gostotno funkcijo normalne porazdelitve. Graf te funkcije smo dobili z izračunom nekega vzorca podatkov v programskem paketu STATISTIKA. Na njem stolpci histograma predstavljajo intervale vrednosti vzorcev, katerih porazdelitev je blizu (ali, kot pravijo v statistiki, se ne razlikujejo bistveno od) samemu grafu funkcije gostote normalne porazdelitve, ki je rdeča krivulja. Graf kaže, da je ta krivulja res zvonasta.
Normalna porazdelitev je dragocena v mnogih pogledih, saj lahko z poznavanjem le srednje vrednosti neprekinjene naključne spremenljivke in standardnega odklona izračunate katero koli verjetnost, povezano s to spremenljivko.
Običajna porazdelitev ima dodatno prednost, da je ena najpreprostejših za uporabo statistični kriteriji za preverjanje statističnih hipotez - Studentov t-test- se lahko uporablja samo v primeru, ko vzorčni podatki ustrezajo normalnemu zakonu porazdelitve.
Funkcija gostote normalne porazdelitve neprekinjene naključne spremenljivke lahko najdete s formulo:
 ,
,
kje x- vrednost spremenljivke, - povprečna vrednost, - standardni odklon, e\u003d 2,71828 ... - osnova naravnega logaritma, \u003d 3,1416 ...
Lastnosti funkcije gostote normalne porazdelitve

Spremembe srednje vrednosti premaknejo krivuljo funkcije gostote normalne porazdelitve v smeri osi Ox. Če se poveča, se krivulja premakne v desno, če se zmanjša, nato v levo.
Če se spremeni standardni odklon, se spremeni višina oglišča krivulje. Ko se standardna deviacija poveča, je vrh krivulje višji, ko se zmanjša, pa nižji.
Verjetnost, da bo vrednost normalno porazdeljene naključne spremenljivke padla v dani interval
Že v tem odstavku bomo začeli reševati praktične probleme, katerih pomen je naveden v naslovu. Analizirajmo, kakšne možnosti ponuja teorija za reševanje problemov. Začetni koncept za izračun verjetnosti, da normalno porazdeljena naključna spremenljivka pade v dani interval, je integralna funkcija normalne porazdelitve.
Integralna funkcija normalne porazdelitve:
 .
.
Vendar je problematično pridobiti tabele za vsako možno kombinacijo srednje vrednosti in standardnega odklona. Zato je eden od preprostih načinov za izračun verjetnosti, da normalno porazdeljena naključna spremenljivka pade v dani interval, uporaba tabel verjetnosti za standardizirano normalno porazdelitev.
Normalna porazdelitev se imenuje standardizirana ali normalizirana porazdelitev., katerega povprečna vrednost je , in standardni odklon je .
Funkcija gostote standardizirane normalne porazdelitve:
 .
.
Kumulativna funkcija standardizirane normalne porazdelitve:
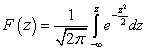 .
.
Spodnja slika prikazuje integralno funkcijo standardizirane normalne porazdelitve, katere graf smo dobili z izračunom nekega vzorca podatkov v programskem paketu STATISTIKA. Sam graf je rdeča krivulja in vzorčne vrednosti se ji približujejo.

Če želite sliko povečati, jo lahko kliknete z levim gumbom miške.
Standardizacija naključne spremenljivke pomeni prehod od prvotnih enot, uporabljenih v nalogi, na standardizirane enote. Standardizacija se izvaja po formuli
V praksi vse možne vrednosti naključne spremenljivke pogosto niso znane, zato vrednosti povprečja in standardnega odklona ni mogoče natančno določiti. Zamenjata jih aritmetična sredina opazovanj in standardni odklon s. vrednost z izraža odstopanja vrednosti naključne spremenljivke od aritmetične sredine pri merjenju standardnih odstopanj.
Odprti interval
Tabela verjetnosti za standardizirano normalno porazdelitev, ki je na voljo v skoraj vsaki knjigi o statistiki, vsebuje verjetnosti, da ima naključna spremenljivka standardno normalno porazdelitev Z prevzame vrednost, manjšo od določenega števila z. To pomeni, da bo padel v odprti interval od minus neskončnosti do z. Na primer, verjetnost, da je vrednost Z manj kot 1,5 je enako 0,93319.
Primer 1 Podjetje izdeluje dele, ki imajo normalno porazdeljeno življenjsko dobo s povprečjem 1000 in standardnim odklonom 200 ur.
Za naključno izbrani del izračunajte verjetnost, da bo njegova življenjska doba najmanj 900 ur.
Odločitev. Naj predstavimo prvi zapis:
Želena verjetnost.
Vrednosti naključne spremenljivke so v odprtem intervalu. Lahko pa izračunamo verjetnost, da bo naključna spremenljivka vzela vrednost, manjšo od dane, in glede na pogoj problema je treba najti enako ali večjo od dane. To je drugi del prostora pod zvonasto krivuljo. Zato je za iskanje želene verjetnosti potrebno od ene odšteti omenjeno verjetnost, da bo naključna spremenljivka prevzela vrednost, manjšo od podanih 900:
Zdaj je treba naključno spremenljivko standardizirati.
Nadaljujemo z uvajanjem zapisa:
z = (X ≤ 900)
;
x= 900 - podana vrednost naključne spremenljivke;
μ
= 1000 - povprečna vrednost;
σ
= 200 - standardni odklon.
Na podlagi teh podatkov dobimo pogoje problema:
 .
.
Glede na tabele standardizirane naključne spremenljivke (meja intervala) z= −0,5 ustreza verjetnosti 0,30854. Odštejte ga od enote in dobite, kar je potrebno v pogoju problema:
Torej je verjetnost, da bo življenjska doba dela vsaj 900 ur, 69%.
To verjetnost lahko dobimo s funkcijo MS Excel NORM.DIST (vrednost integralne vrednosti je 1):
P(X≥900) = 1 - P(X≤900) = 1 - NORM.DIST(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
O izračunih v MS Excelu - v enem od naslednjih odstavkov te lekcije.
Primer 2 V določenem mestu je povprečni letni družinski dohodek normalno porazdeljena naključna spremenljivka s srednjo vrednostjo 300 000 in standardnim odklonom 50 000. Znano je, da je dohodek 40 % družin manjši od vrednosti A. Poiščite vrednost A.
Odločitev. V tem problemu 40 % ni nič drugega kot verjetnost, da bo naključna spremenljivka vzela vrednost iz odprtega intervala, ki je manjša od določene vrednosti, označene s črko A.
Da bi našli vrednost A, najprej sestavimo integralno funkcijo:

Glede na nalogo
μ
= 300000 - povprečna vrednost;
σ
= 50000 - standardni odklon;
x = A je vrednost, ki jo je treba najti.
Ustvarjanje enakosti
 .
.
Glede na statistične tabele ugotovimo, da verjetnost 0,40 ustreza vrednosti intervalne meje z = −0,25
.
Zato naredimo enakost

in poiščite njegovo rešitev:
A = 287300
.
Odgovor: dohodek 40% družin je manjši od 287300.
Zaprt interval
V številnih težavah je treba najti verjetnost, da normalno porazdeljena naključna spremenljivka zavzame vrednost v intervalu od z 1 do z 2. To pomeni, da bo padel v zaprti interval. Za reševanje takšnih problemov je treba v tabeli najti verjetnosti, ki ustrezajo mejam intervala, in nato poiskati razliko med temi verjetnostmi. To zahteva odštevanje manjše vrednosti od večje. Primeri za reševanje teh pogostih težav so naslednji, predlaga se, da jih rešite sami, nato pa lahko vidite pravilne rešitve in odgovore.
Primer 3 Dobiček podjetja za določeno obdobje je naključna spremenljivka, za katero velja običajni zakon o razdelitvi, s povprečno vrednostjo 0,5 milijona c.u. in standardni odklon 0,354. Z natančnostjo dveh decimalnih mest določite verjetnost, da bo dobiček podjetja od 0,4 do 0,6 c.u.
Primer 4 Dolžina izdelanega dela je naključna spremenljivka, porazdeljena po normalnem zakonu s parametri μ
=10 in σ
=0,071. Z natančnostjo dveh decimalnih mest poiščite verjetnost poroke, če bi morale biti dovoljene dimenzije dela 10 ± 0,05.
Namig: pri tem problemu je poleg iskanja verjetnosti, da naključna spremenljivka pade v zaprt interval (verjetnost pridobitve dela brez napake), potrebno še eno dejanje.

vam omogoča, da določite verjetnost, da je standardizirana vrednost Z ne manj -z in nič več +z, kje z- poljubno izbrana vrednost standardizirane naključne spremenljivke.
Približna metoda za preverjanje normalnosti porazdelitve
Približna metoda za preverjanje normalnosti porazdelitve vzorčnih vrednosti temelji na naslednjem lastnost normalne porazdelitve: poševnost β
1
in koeficient ekscesa β
2
nič.
Koeficient asimetrije β
1
številčno označuje simetrijo empirične porazdelitve glede na povprečje. Če je poševnost enaka nič, so aritmetrična sredina, mediana in moda enaki: krivulja gostote porazdelitve pa je simetrična glede na povprečje. Če je koeficient asimetrije manjši od nič (β
1
< 0
), potem je aritmetična sredina manjša od mediane, mediana pa je manjša od načina () in krivulja je premaknjena v desno (v primerjavi z normalno porazdelitvijo). Če je koeficient asimetrije večji od nič (β
1
> 0
), potem je aritmetična sredina večja od mediane, mediana pa je večja od načina () in krivulja se premakne v levo (v primerjavi z normalno porazdelitvijo).
Kurtosis koeficient β
2
označuje koncentracijo empirične porazdelitve okoli aritmetične sredine v smeri osi oj in stopnja vrha krivulje gostote porazdelitve. Če je koeficient kurtoze večji od nič, je krivulja bolj podaljšana (v primerjavi z normalno porazdelitvijo) vzdolž osi oj(graf je bolj poudarjen). Če je koeficient kurtoze manjši od nič, je krivulja bolj sploščena (v primerjavi z normalno porazdelitvijo) vzdolž osi oj(graf je bolj tup).
Koeficient poševnosti lahko izračunamo s funkcijo MS Excel SKRS. Če preverjate en niz podatkov, morate v eno polje »Število« vnesti obseg podatkov.

Koeficient kurtosis lahko izračunamo z uporabo funkcije MS Excel kurtosis. Pri preverjanju enega podatkovnega niza je dovolj tudi, da obseg podatkov vnesete v eno polje »Število«.

Torej, kot že vemo, sta pri normalni porazdelitvi koeficienta poševnosti in kurtosis enaka nič. Kaj pa, če imamo koeficiente poševnosti enake -0,14, 0,22, 0,43 in koeficiente kurtosis enake 0,17, -0,31, 0,55? Vprašanje je precej pošteno, saj imamo v praksi opravka le s približnimi, selektivnimi vrednostmi asimetrije in kurtosis, ki so podvrženi nekemu neizogibnemu, neobvladljivemu razprševanju. Zato je nemogoče zahtevati strogo enakost teh koeficientov nič, morajo biti le dovolj blizu nič. Toda kaj pomeni dovolj?
Prejete empirične vrednosti je treba primerjati z dopustnimi vrednostmi. Če želite to narediti, morate preveriti naslednje neenakosti (primerjajte vrednosti koeficientov po modulu s kritičnimi vrednostmi - mejami območja za testiranje hipoteze).
Za koeficient asimetrije β
1
.
) igra posebno pomembno vlogo v teoriji verjetnosti in se najpogosteje uporablja pri reševanju praktičnih problemov. Njegova glavna značilnost je, da je omejevalni zakon, ki se mu približujejo drugi zakoni distribucije pod zelo običajnimi tipičnimi pogoji. Na primer, vsota dovolj velikega števila neodvisnih (ali šibko odvisnih) naključnih spremenljivk približno ustreza normalnemu zakonu, in ta je bolj natančen, več naključnih spremenljivk se sešteje.
Eksperimentalno je dokazano, da so napake pri meritvah, odstopanja v geometrijskih dimenzijah in legah elementov gradbenih konstrukcij med njihovo izdelavo in vgradnjo, spremenljivost fizikalnih in mehanskih lastnosti materialov ter obremenitve, ki delujejo na gradbene konstrukcije, predmet normalnega zakona.
Skoraj vse naključne spremenljivke so podvržene Gaussovi porazdelitvi, katere odstopanje od povprečnih vrednosti je posledica velikega nabora naključnih faktorjev, od katerih je vsak posamezno nepomemben. (osrednji mejni izrek).
normalna porazdelitev imenujemo porazdelitev naključne zvezne spremenljivke, za katero ima gostota verjetnosti obliko (slika 18.1).
riž. 18.1. Normalni zakon porazdelitve za 1< a 2 .
kjer sta a in parametra porazdelitve.
Verjetnostne značilnosti naključne spremenljivke, porazdeljene po normalnem zakonu, so:
Matematično pričakovanje (18.2)
Disperzija (18.3)
Standardni odklon (18,4)
Koeficient asimetrije A = 0(18.5)
Presežek E= 0. (18.6)
Parameter σ, vključen v Gaussovo porazdelitev, je enak korenskemu srednje-kvadratnemu razmerju naključne spremenljivke. vrednost a določa položaj distribucijskega centra (glej sliko 18.1) in vrednost a- širina porazdelitve (slika 18.2), t.j. statistično širjenje okoli povprečja.
riž. 18.2. Normalni zakon porazdelitve za σ 1< σ 2 < σ 3
Verjetnost padca v dani interval (od x 1 do x 2) za normalno porazdelitev, kot v vseh primerih, je določena z integralom gostote verjetnosti (18.1), ki ni izražena z elementarnimi funkcijami in je predstavljena s posebno funkcijo, imenovano Laplaceova funkcija (integral verjetnosti).
Ena od predstavitev integrala verjetnosti:
vrednost in poklical kvantil.
Vidimo, da je Ф(х) liha funkcija, t.j. Ф(-х) = -Ф(х) .
Vrednosti te funkcije so izračunane in predstavljene v obliki tabel v tehnični in izobraževalni literaturi.
Funkcijo porazdelitve normalnega zakona (slika 18.3) lahko izrazimo z verjetnostnim integralom:
riž. 18.2. Funkcija zakona normalne porazdelitve.
Verjetnost, da naključna spremenljivka, porazdeljena po normalnem zakonu, pade v interval od X do x, je določeno z izrazom:
Treba je opozoriti, da
Ф(0) = 0; Ф(∞) = 0,5; Ф(-∞) = -0,5.
Pri reševanju praktičnih problemov, povezanih z distribucijo, je treba pogosto upoštevati verjetnost, da pademo v interval, ki je simetričen glede na matematično pričakovanje, če je dolžina tega intervala t.j. če ima interval sam mejo od do , imamo:
Pri reševanju praktičnih problemov so meje odstopanj naključnih spremenljivk izražene s standardom, standardnim odklonom, pomnoženim z določenim faktorjem, ki določa meje območja odstopanj naključne spremenljivke.
Če vzamemo in tudi z uporabo formule (18.10) in tabele F (x) (Dodatek št. 1), dobimo
Te formule kažejo da če ima naključna spremenljivka normalno porazdelitev, potem je verjetnost njenega odstopanja od srednje vrednosti za največ 68,27%, največ 2σ - 95,45% in ne več kot 3σ - 99,73%.
Ker je vrednost 0,9973 blizu enote, je praktično nemogoče, da bi normalna porazdelitev naključne spremenljivke odstopala od matematičnega pričakovanja za več kot 3σ. To pravilo, ki velja samo za normalno porazdelitev, se imenuje pravilo treh sigma. Kršitev je verjetna P = 1 - 0,9973 = 0,0027. To pravilo se uporablja pri določanju meja dovoljenih odstopanj toleranc geometrijskih značilnosti izdelkov in konstrukcij.
Naključno, če lahko zaradi izkušenj z določenimi verjetnostmi prevzame realne vrednosti. Najbolj popolna in izčrpna značilnost naključne spremenljivke je zakon porazdelitve. Zakon distribucije je funkcija (tabela, graf, formula), ki vam omogoča določitev verjetnosti, da naključna spremenljivka X prevzame določeno vrednost xi ali pade v določen interval. Če ima naključna spremenljivka dan zakon porazdelitve, potem pravimo, da je porazdeljena v skladu s tem zakonom ali je podrejena temu zakonu o porazdelitvi.
Vsi distribucijski zakon je funkcija, ki v celoti opisuje naključno spremenljivko z verjetnostnega vidika. V praksi je verjetnostno porazdelitev naključne spremenljivke X pogosto treba presojati le po rezultatih testa.
Normalna porazdelitev
Normalna porazdelitev, imenovana tudi Gaussova porazdelitev, je verjetnostna porazdelitev, ki igra ključno vlogo na številnih področjih znanja, zlasti v fiziki. Fizična količina je podvržena normalni porazdelitvi, ko nanjo vpliva ogromno naključnih šumov. Jasno je, da je ta situacija izjemno pogosta, zato lahko rečemo, da se od vseh porazdelitev v naravi najpogosteje pojavlja normalna porazdelitev – od tod izhaja eno od njenih imen.
Normalna porazdelitev je odvisna od dveh parametrov - odmika in obsega, torej z matematičnega vidika ne gre za eno porazdelitev, ampak za njihovo celotno družino. Vrednosti parametrov ustrezajo srednji vrednosti (matematično pričakovanje) in razmiku (standardni odklon).


Standardna normalna porazdelitev je normalna porazdelitev s povprečno vrednostjo 0 in standardnim odklonom 1.


Koeficient asimetrije

Koeficient poševnosti je pozitiven, če je desni rep porazdelitve daljši od levega, drugače pa negativen.
Če je porazdelitev simetrična glede na matematično pričakovanje, je njen koeficient poševnosti enak nič.

Koeficient poševnosti vzorca se uporablja za preverjanje simetrije porazdelitve, pa tudi za grobi predhodni preizkus normalnosti. Omogoča vam, da zavrnete, vendar vam ne dovoli, da sprejmete hipotezo o normalnosti.
Kurtosis koeficient

Koeficient kurtosis (koeficient ostrine) je merilo ostrine vrha porazdelitve naključne spremenljivke.
"Minus tri" na koncu formule je uveden tako, da je koeficient kurtoze normalne porazdelitve enak nič. Pozitiven je, če je vrh porazdelitve blizu pričakovane vrednosti oster, in negativen, če je vrh gladek.

Trenutki naključne spremenljivke
Trenutek naključne spremenljivke je numerična značilnost porazdelitve dane naključne spremenljivke.