Rubriques du site
Le choix des éditeurs:
- Se débarrasser des sous-vêtements : comment se passer de soutien-gorge en été Comment porter des hauts sans soutien-gorge
- Irina Shayk : chirurgie plastique ou pas ?
- Nous demandons à la police de joindre ces photos à l'affaire !
- Yana Koshkina: biographie, vie personnelle, famille, mari, enfants - photo
- Événements de la semaine de Knizhkina de l'année où seront
- Les robes de célébrités les plus révélatrices et les plus risquées (28 photos) Les tenues de célébrités les plus révélatrices
- Les robes de célébrités les plus révélatrices et les plus risquées (28 photos)
- Événement inter-écoles dédié à la journée de l'astronautique
- Photos sexy d'Amanda seyfried divulguées en ligne Photos icloud d'Amanda seyfried divulguées
- Types d'avatars et nature de leur propriétaire
Publicité
| Classification des services réseau par critère temporel. Services réseau et services réseau |
|
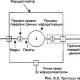
La tâche de la couche de données est de fournir des services à la couche réseau. Le service principal est le transfert de données de la couche réseau de la machine émettrice vers la couche réseau de la machine réceptrice. Une entité ou un processus s'exécute sur la machine émettrice, qui transfère les bits de la couche réseau à la couche données pour transmission vers leur destination. Le travail de la couche liaison de données consiste à transmettre ces bits à la machine réceptrice afin qu'ils puissent être transmis à la couche réseau de la machine réceptrice, comme illustré à la figure 2. 3.2, un. En réalité, les données sont transférées le long du chemin illustré à la Fig. 3.2, b, cependant, il est plus facile d'imaginer deux couches de transfert de données communiquant entre elles à l'aide d'un protocole de transfert de données. Pour cette raison, tout au long de ce chapitre, le modèle illustré à la Fig. 3.2, un. La couche liaison de données peut fournir divers services. Leur ensemble peut être différent dans différents systèmes. Les options suivantes sont généralement possibles. 1. Service sans confirmations, sans établissement de connexion. 2. Service avec confirmations, sans établissement de connexion. 3. Service avec confirmations, orienté connexion. Considérons ces options à tour de rôle. Le service sans accusé de réception et sans connexion est que la machine émettrice envoie des trames indépendantes à la machine réceptrice, et la machine réceptrice n'envoie pas d'accusé de réception de trames. Aucune connexion n'est préétablie ou interrompue après la transmission des trames. Si une trame est perdue en raison d'un bruit de ligne, aucune tentative n'est faite au niveau de la couche liaison de données pour la récupérer. Cette classe de service est acceptable avec un taux d'erreur très faible. Dans ce cas, les problèmes liés à la récupération des données perdues lors de la transmission peuvent être laissés aux couches supérieures. Il est également utilisé dans les communications en temps réel, telles que la voix, où il est préférable de recevoir des données brouillées que de les recevoir avec un long retard. Un service sans connexion et sans accusé de réception est utilisé dans la couche de données de la plupart des réseaux locaux. La prochaine étape vers une fiabilité accrue est un service avec confirmations, sans établir de connexion. Lors de son utilisation, la connexion n'est pas non plus établie, mais la réception de chaque trame est acquittée. Ainsi, l'expéditeur sait si la trame a atteint sa destination intacte. Si aucun accusé de réception n'est reçu dans l'intervalle de temps défini, la trame est à nouveau envoyée. Ce service est utile lors de l'utilisation de canaux à forte probabilité d'erreur, comme dans les systèmes sans fil. Il convient probablement de noter que fournir des confirmations est plus une optimisation qu'une exigence. La couche réseau peut toujours envoyer un paquet et attendre la confirmation de sa livraison. Si la confirmation n'est pas reçue par l'expéditeur dans le délai spécifié, le message peut être renvoyé. Le problème avec cette stratégie est que les trames ont généralement une limite de longueur maximale stricte en raison des exigences matérielles. Les paquets de la couche réseau n'ont pas de telles restrictions. Ainsi, si le message moyen est divisé en 10 trames et que 20 % d'entre elles sont perdues en cours de route, alors la transmission du message par cette méthode peut prendre très longtemps. En reconnaissant les trames individuelles et en les renvoyant en cas d'erreur, la transmission de l'intégralité du message prendra beaucoup moins de temps. Dans les liaisons fiables telles que les câbles à fibre optique, la surcharge d'accusé de réception au niveau de la couche de données ne fera que réduire le débit de la liaison, mais pour les communications sans fil, ces coûts seront payants et réduiront le temps de transmission des longs messages. Le service le plus complexe que la couche de données peut fournir est un service orienté connexion avec accusés de réception. Avec cette méthode, la source et la destination établissent une connexion avant de s'envoyer des données. Chaque trame envoyée est numérotée et la couche liaison s'assure que chaque trame envoyée est effectivement reçue de l'autre côté de la liaison. De plus, il est garanti que chaque trame n'a été reçue qu'une seule fois et que toutes les trames ont été reçues dans le bon ordre. Dans un service sans connexion, en revanche, il est possible qu'en cas de perte d'un acquittement, la même trame soit émise plusieurs fois et donc reçue plusieurs fois. Un service orienté connexion fournit aux processus de la couche réseau l'équivalent d'un flux binaire fiable. Lors de l'utilisation d'un service orienté connexion, le transfert de données se compose de trois phases différentes. Dans la première phase, la connexion est établie, les deux côtés initialisant les variables et les compteurs nécessaires pour garder une trace des trames qui ont été reçues et de celles qui ne l'ont pas été. Dans la deuxième phase, des trames de données sont transmises. Enfin, dans la troisième phase, la connexion est terminée et toutes les variables, tampons et autres ressources utilisées pendant la connexion sont libérées. Prenons un exemple typique : un réseau global composé de routeurs connectés de nœud à nœud par des lignes téléphoniques dédiées. Lorsqu'une trame arrive au routeur, le matériel vérifie les erreurs (en utilisant une méthode que nous explorerons dans un instant) et transmet la trame au logiciel de couche de données (qui peut être intégré dans une puce de carte réseau). Le programme de la couche de données vérifie s'il s'agit de la trame attendue et, si c'est le cas, transmet le paquet stocké dans le champ de charge utile de la trame au programme de routage. Le programme de routage sélectionne la ligne sortante souhaitée et renvoie le paquet au programme de couche de données, qui le transmet plus loin à travers le réseau. Le passage d'un message à travers deux routeurs est illustré à la Fig. 3.3.
Les programmes de routage doivent souvent faire le travail correctement, c'est-à-dire qu'ils ont besoin d'une connexion fiable avec des paquets ordonnés sur toutes les liaisons reliant les routeurs. De tels programmes sont généralement détestés si vous devez trop souvent vous soucier des paquets perdus. Rendre les liaisons non fiables fiables, ou du moins assez bonnes, est la tâche de la couche liaison de données, représentée sur la figure par la boîte en pointillés. Notez que bien que la figure montre plusieurs copies du programme de couche de données, en fait, tous les liens sont desservis par une copie du programme avec différentes tables et structures de données pour chaque lien. En savoir plus sur le thème Services fournis à la couche réseau :
Un centre de données est un emplacement physique où les ressources informatiques critiques sont collectées. Le centre est conçu pour prendre en charge les applications critiques et leurs ressources informatiques associées, telles que les mainframes, les serveurs et les batteries de serveurs. Les applications métier incluent les applications financières, RH, e-commerce et interentreprises. En plus de ces groupes de serveurs qui prennent en charge les applications métier, il existe d'autres groupes de serveurs qui prennent en charge les services réseau et les applications réseau. Les services réseau incluent NTP, Telnet, FTP, DNS, DHCP, SNMP, TFTP et NFS. Les applications réseau sont la téléphonie IP, la vidéo sur IP, les systèmes de visioconférence, etc. Une application métier fait référence à toute application qui exécute des fonctions nécessaires à une entreprise, ce qui signifie généralement un très grand nombre de ces applications. Certaines applications d'entreprise sont logiquement organisées en plusieurs niveaux, qui sont séparés par les fonctions qu'ils exécutent. Certaines couches sont dédiées à la prise en charge des appels client ou des fonctions externes telles que la diffusion de pages Web ou la prise en charge de l'interface de ligne de commande (CLI) pour les applications. Dans certains cas, des fonctions externes peuvent être implémentées sur la base du Web. D'autres fonctions gèrent les demandes des utilisateurs et les convertissent dans un format compréhensible par des couches telles que la couche serveur ou la couche base de données. Une telle approche à plusieurs niveaux est appelée modèle à N niveaux, car en plus des niveaux externe et interne, il peut y avoir plusieurs autres niveaux entre eux. De tels niveaux sont associés à la gestion des objets, de leurs relations, contrôlent l'interaction avec la base de données, offrent les interfaces nécessaires aux applications. Les applications d'entreprise relèvent généralement de l'un des principaux domaines d'activité suivants :
Source : Cisco Il convient de noter que la couche externe, qui prend en charge les appels des clients vers le serveur, prend en charge les applications d'accès. Actuellement, il existe à la fois des applications natives et basées sur le Web, et il y a une tendance vers les applications basées sur le Web. Cette tendance implique qu'une interface Web est utilisée pour travailler avec les clients, mais en même temps, les applications ont un niveau intermédiaire qui, à la demande d'un client, reçoit des informations d'une base de données interne et les transmet à un niveau externe, par exemple , un serveur Web, apportant, donc la réponse appartient au client. Cette couche intermédiaire d'applications et de systèmes de base de données est une partie logiquement séparée qui exécute des fonctions spécifiques. La séparation logique de ces fonctions rend possible la séparation physique. Et l'essentiel est que les serveurs d'applications et les serveurs Web n'ont plus besoin de se trouver au même emplacement physique. Cette séparation augmente l'évolutivité des services et simplifie la gestion de grands groupes de serveurs. Du point de vue du réseau, de tels groupes de serveurs qui exécutent différentes fonctions peuvent être physiquement séparés en différents niveaux du réseau pour des raisons de sécurité et de facilité de gestion. Sur la Fig. 10 Le niveau intermédiaire et le niveau base de données fournissent une connectivité réseau à chaque groupe de serveurs. Capacités du centre de données Étant donné que ces emplacements hébergent des ressources informatiques critiques, des efforts particuliers doivent être faits pour former le personnel et les installations afin de fournir une assistance 24 heures sur 24. L'objet de l'assistance sont les ressources informatiques et réseau. La spécificité de ces ressources et leur importance pour faire des affaires nécessitent une attention particulière aux domaines suivants :
Le personnel de travail doit être composé de spécialistes qui ont bien étudié les exigences de gestion du centre et de suivi de son travail. En plus des zones de service ci-dessus, il est nécessaire de mentionner:
Infrastructure de réseau L'infrastructure requise pour prendre en charge les ressources informatiques est largement déterminée par l'ensemble des services du centre de données qui servent à atteindre les objectifs de l'architecture. Les principaux composants de l'infrastructure réseau sont alors regroupés par les mêmes services. La liste des composants de l'infrastructure réseau définit un ensemble de services, mais en soi, elle est très longue et il est plus pratique de la décrire en décrivant les détails de chaque service. Avantages de la construction de centres de données Les avantages des centres de données peuvent être résumés en une phrase : "Un centre de données consolide les ressources informatiques critiques dans un environnement sécurisé pour une gestion centralisée, permettant à l'entreprise de fonctionner de manière autonome, y compris 24 heures sur 24." Un fonctionnement 24 heures sur 24 est supposé pour tous les services qui prennent en charge le centre de données. L'activité commerciale normale est soutenue par des applications commerciales critiques, en l'absence desquelles l'entreprise souffre gravement ou s'arrête complètement. La construction d'un centre nécessite une planification sérieuse. Les stratégies d'efficacité, d'évolutivité, de sécurité et de gouvernance doivent être claires et explicitement alignées sur les exigences de l'entreprise. La perte d'accès à des informations importantes peut être quantifiée, car elle affecte le résultat - le revenu. Certaines entreprises sont tenues par la loi de planifier la continuité de leurs activités : agences fédérales, institutions financières, soins de santé, etc. Les conséquences dévastatrices d'une éventuelle perte d'accès à l'information obligent les entreprises à rechercher des moyens de réduire ce risque et son impact sur l'activité. Une grande partie des plans envisagent l'utilisation de centres de données, qui couvrent les ressources informatiques critiques. Mikhaïl Kader / Cisco L'ensemble des parties serveur et client du système d'exploitation qui permettent d'accéder à un type spécifique de ressource informatique via un réseau est appelé service réseau. Dans l'exemple ci-dessus, les parties client et serveur du système d'exploitation, qui fournissent ensemble un accès réseau au système de fichiers de l'ordinateur, forment un service de fichiers. On dit que le service de réseau fournit aux utilisateurs du réseau un ensemble de prestations de service. Ces services sont également appelés service réseau(du terme anglais "service"). Bien que ces termes soient parfois utilisés de manière interchangeable, il convient de garder à l'esprit que, dans certains cas, la différence de sens entre ces termes est de nature fondamentale. Plus loin dans le texte, par « service », nous entendons un composant réseau qui met en œuvre un certain ensemble de services, et par « service », nous entendons une description de l'ensemble des services fournis par ce service. Ainsi, un service est une interface entre un consommateur de service et un fournisseur de service (service). Chaque service est associé à un type spécifique de ressources réseau et/ou à une manière spécifique d'accéder à ces ressources. Par exemple, le service d'impression permet aux utilisateurs du réseau d'accéder à des imprimantes réseau partagées et fournit un service d'impression, et le service de messagerie permet d'accéder à la ressource d'informations du réseau - les e-mails. La méthode d'accès aux ressources est différente, par exemple le service d'accès à distance - il permet aux utilisateurs d'un réseau informatique d'accéder à toutes ses ressources via des canaux téléphoniques commutés. Pour obtenir un accès à distance à une ressource spécifique, telle qu'une imprimante, le service d'accès à distance communique avec le service d'impression. Les plus importants pour les utilisateurs du système d'exploitation réseau sont le service de fichiers et le service d'impression. Parmi les services réseau, on peut distinguer ceux qui ne sont pas centrés sur un simple utilisateur, mais sur un administrateur. Ces services sont utilisés pour organiser le fonctionnement du réseau. Par exemple, le service Novell NetWare 3.x Bindery permet à un administrateur de gérer une base de données d'utilisateurs du réseau sur un ordinateur exécutant Novell NetWare 3.x. Une approche plus progressive consiste à créer un service d'assistance centralisé ou, en d'autres termes, un service d'annuaire, conçu pour maintenir une base de données non seulement sur tous les utilisateurs du réseau, mais également sur tous ses composants logiciels et matériels. Le NDS de Novell est souvent cité comme exemple de service d'annuaire. D'autres exemples de services réseau qui fournissent un service à l'administrateur sont un service de surveillance du réseau qui permet de capturer et d'analyser le trafic réseau, un service de sécurité qui peut inclure, notamment, une procédure de connexion logique avec vérification du mot de passe, un service de sauvegarde et d'archivage . La richesse d'un ensemble de services qu'un système d'exploitation offre aux utilisateurs finaux, aux applications et aux administrateurs réseau détermine sa position dans la gamme globale des systèmes d'exploitation réseau. Les services réseau sont, par nature, des systèmes client-serveur. Étant donné que lors de la mise en œuvre de tout service réseau, une source de demande (client) et un exécuteur de demande (serveur) apparaissent naturellement, tout service réseau contient également deux parties asymétriques - client et serveur. Un service réseau peut être représenté dans le système d'exploitation soit par les deux parties (client et serveur), soit par une seule d'entre elles. On dit généralement que le serveur fournit ses ressources au client et que le client les utilise. Il convient de noter que lorsqu'un service réseau fournit un certain service, les ressources non seulement du serveur, mais également du client sont utilisées. Le client peut consacrer une partie importante de ses ressources (espace disque, temps processeur, etc.) à la maintenance du service réseau. La différence fondamentale entre un client et un serveur est que le service réseau est toujours lancé par le client, tandis que le serveur attend toujours passivement les requêtes. Par exemple, un serveur de messagerie distribue le courrier à l'ordinateur de l'utilisateur uniquement lorsqu'une demande est reçue du client de messagerie. En règle générale, l'interaction entre le client et le serveur est standardisée de sorte qu'un type de serveur peut être conçu pour fonctionner avec différents types de clients, mis en œuvre de différentes manières et même par différents fabricants. La seule condition pour cela est que les clients et le serveur doivent prendre en charge un protocole de communication standard commun. l'Internet- un réseau mondial unique qui relie un grand nombre de réseaux à travers le monde (de l'anglais. Internet - "internet", "réseau de réseaux"). L'Internet est né dans les années 1960 aux États-Unis à la suite d'expériences visant à créer un réseau viable qui ne pouvait pas être désactivé en détruisant un ou plusieurs postes de commandement avec des ordinateurs centraux. L'Internet est un réseau décentralisé qui n'a pas de propriétaire ou d'organe de gestion (bien que chaque réseau qui y est inclus ait un propriétaire et un administrateur système), fonctionnant et se développant grâce à la coopération volontaire (y compris commerciale) de diverses organisations et utilisateurs sur la base d'accords communs et normes (protocoles). ). Les normes, protocoles, spécifications enregistrés et numérotés du formulaire Internet Système de documents électroniques RFC(Demande de commentaires - demande de clarification). Organismes assurant la connexion et la fourniture de services Internet – fournisseurs(eng. Internet Service Providers, Internet Service Providers) sont connectés canaux principaux à grande vitesse(câble, fibre optique, satellite, relais radio). Un ordinateur séparé ou un réseau local peut se connecter au fournisseur via ligne louée(connexion permanente) ou par ligne commutée(connexion temporaire via modem et réseau téléphonique régulier). La première méthode est plus coûteuse, mais offre un taux de transfert de données plus élevé. Le signal modem peut être transmis : Via le canal téléphonique habituel ligne commutée; · au ligne téléphonique dédiée; · sur le socle Technologies ADSL(eng. Ligne d'abonné numérique asymétrique - une ligne d'abonné numérique asymétrique) sur un canal téléphonique ordinaire, sans l'occuper et vous permettant de mener des conversations téléphoniques indépendamment et simultanément. La vitesse de transfert de données via une ligne téléphonique commutée est d'environ 30 Kbps pour les lignes téléphoniques analogiques et de 60 à 120 Kbps pour les lignes numériques. Pour les lignes téléphoniques dédiées, la vitesse de transmission peut atteindre 2 Mbps, pour les lignes de communication par fibre optique et par satellite - des centaines de Mbps. Les connexions permanentes, en fonction de l'équipement réseau utilisé et du type de canal câblé, offrent des taux de transfert de données allant jusqu'à 20-40 Mbps et plus. Internet est basé sur protocole TCP/IP de base, introduit en 1983. En fait, TCP/IP est un ensemble de protocoles et se compose de plusieurs couches de base. Alors, Protocole de transport TCP(Transmission Control Protocol - protocole de contrôle de transmission) permet de diviser les données en petits paquets ( segments) avant expédition et assemblage après livraison, et Protocole de routage IP(Internet Protocol - Internet Protocol) est responsable du choix des itinéraires à travers différents nœuds et réseaux entre l'expéditeur et le destinataire (éventuellement différents pour différents paquets du même message). Les paquets de données préparés à l'aide de ce protocole sont appelés Datagrammes IP(ou paquets IP). Ils comprennent des segments préparés à l'aide du protocole TCP, auxquels sont ajoutées les adresses de l'expéditeur et du destinataire. Ces protocoles effectuent également d'autres tâches, par exemple, le protocole TCP comprend des fonctions non seulement de la couche de transport, mais également de la couche de session, ne s'intégrant pas entièrement dans la stratification du modèle OSI, car elles ont été développées avant son apparition. Chacun des services d'information (services d'information) d'Internet résout ses problèmes en utilisant son protocoles d'application basé sur les protocoles TCP/IP sous-jacents. Le plus célèbre d'entre eux : · "World Wide Web" www(du World Wide Web anglais) permet de déplacer des documents, des livres, des nouvelles, des photographies, des dessins, des cours de formation, des documents de référence, etc. dans l'espace d'information ; A l'heure actuelle, le WWW prétend en effet être le principal vecteur de la "mémoire collective" de l'humanité. Le service www utilise protocole http et discuté plus en détail ci-dessous. · E-mail ou E-mail(de l'anglais. Courrier électronique) permet d'échanger des e-mails sur le réseau, qui peuvent être accompagnés de fichiers supplémentaires. En utilisant le service E-mail, vous pouvez également envoyer des messages à un téléphone portable, un communicateur, un fax, un téléavertisseur. Utilisé pour envoyer du courrier Protocole SMTP(Eng. Simple Mail Transfer Protocol - un protocole de transfert de courrier simple), pour le recevoir de votre boîte aux lettres à serveur de courrier – Protocole POP(eng. Post Office Protocol - protocole de bureau de poste). Protocole IMAP(Internet Message Access Protocol - Internet Message Access Protocol) vous permet de stocker le courrier dans votre boîte aux lettres sur un serveur de messagerie. Pour joindre des fichiers arbitraires à un e-mail, utilisez Norme MIME(Extension de messagerie Internet polyvalente - extension de messagerie Internet polyvalente). Les règles de génération d'adresses e-mail sont décrites ci-dessous. Utilisé pour travailler avec le courrier électronique programmes de messagerie Outlook Express (inclus dans Microsoft Internet Explorer), Microsoft Outlook (inclus dans Microsoft Office), Netscape Messenger (inclus dans le navigateur Netscape Communicator), The Bat! autre Courriel. · Service de transfert de fichiers entre ordinateurs distants utilisé pour transférer des fichiers volumineux (archives, livres, etc.) via Protocole FTP(eng. File Transfer Protocol - protocole de transfert de fichiers). Pour travailler avec FTP, vous avez besoin Client FTP, qui peut être intégré dans un navigateur Web, un gestionnaire de fichiers ou fourni en tant qu'application distincte. Les clients FTP diffèrent dans leur capacité à utiliser multithreading(téléchargement de parties de fichiers dans plusieurs processus parallèles), prise en charge de la "reprise" d'un fichier après une rupture de connexion, restrictions sur la taille de fichier maximale prise en charge. · Service de téléconférence (actualités, newsgroups) UseNet News (Newsgroups) fournit la visualisation de documents sur le sujet sélectionné, envoyés au serveur de téléconférence par les utilisateurs eux-mêmes. Également utilisé listes de diffusion, formé avec la participation de l'administrateur ( modérateur) conférences et envoyées aux abonnés. Avant l'omniprésence d'Internet, les fonctions de la téléconférence étaient en grande partie assurées par Babillards BBS(Eng. Bulletin Board System - un système de bulletins électroniques), dont le système le plus célèbre est le réseau FidoNet. La connexion au BBS s'effectue sur de petits réseaux informatiques avec un serveur utilisant des modems via des lignes téléphoniques. · Service de communication interactive IRC(Internet Relay Chat - littéralement, bavardage diffusé sur Internet), qui est souvent appelé conférences de chat ou simplement discuter, entretient une conversation collective dont les participants tapent leurs lignes sur le clavier et voient ce que les autres ont dit sur le moniteur. · Système de radiomessagerie Internet ICQ(de l'anglais « I seek you » - je te cherche, « ICQ » dans le jargon des internautes domestiques) permet d'échanger messages et fichiers en temps réel. Ce système permet de rechercher l'adresse réseau de l'abonné (permanent ou temporaire), s'il est actuellement connecté au réseau, par son numéro d'identification personnel UIN(Eng. Universal Internet Number), reçu lors de l'inscription sur le serveur central de ce service. · Service Telnet sert de télécommande Protocole Telnet) via Internet par d'autres ordinateurs et programmes installés sur ceux-ci, par exemple connectés à des équipements permettant de mener des expériences ou d'effectuer des calculs mathématiques complexes. · Les principaux domaines d'utilisation d'Internet sont Téléphonie Internet (téléphonie IP)– transmission de conversations téléphoniques et de fax sur Internet dans un cryptage correspondant au protocole IP, diffusion de programmes de radio et de télévision sur Internet, connexion Internet sans fil à partir de téléphones mobiles : directement via Protocole WAP(Wireless Application Protocol), ou via un ordinateur via Protocole GPRS(Service général de radiocommunication par paquets). Le cryptage des informations transmises sur Internet est fourni Protocole SSL(Couche de socket sécurisée). Chaque ordinateur connecté à Internet reçoit un message unique (non répétitif) adresse IP(c'est-à-dire une adresse IP). Avec une connexion permanente, cette adresse lui est attribuée, avec une connexion temporaire, une adresse temporaire (dynamique) est attribuée pour la session. Dans le même temps, un ordinateur connecté en permanence au réseau et via lequel les utilisateurs temporaires se connectent est appelé serveur(de l'hôte anglais - le propriétaire). Adresse IP physique est un nombre binaire de 32 bits (4 octets), qui est généralement écrit en convertissant chaque octet en un nombre décimal et en les séparant par des points. Ce numéro encode le réseau par lequel l'ordinateur accède à Internet et le numéro de l'ordinateur sur le réseau. Selon le nombre autorisé d'ordinateurs, les réseaux sont divisés en trois classes (tableau 3). Tableau 3. Classes de réseau A, B, C Par exemple, l'adresse 197.98.140.101 correspond au numéro de nœud 0.0.0.101 sur le réseau de classe C 197.98.140.0. Pour séparer l'adresse réseau de l'adresse hôte, utilisez Masque de sous-réseau, qui est également un nombre 32 bits. Par défaut, les réseaux de classe A correspondent au masque 255.0.0.0, classe B - 255.255.0.0 et réseaux de classe C - 255.255.255.0, c'est-à-dire que dans la représentation binaire du masque, les positions correspondant à l'adresse réseau sont fermées par les uns. Le masque de sous-réseau peut également être utilisé à d'autres fins, telles que la subdivision logique des réseaux locaux en sous-réseaux plus petits. Plusieurs adresses IP sont réservées à des fins particulières, telles que adresse 127.0.0.1 renvoie l'utilisateur à lui-même (utilisé pour tester des programmes et déboguer des applications Web sur un serveur local). Un numéro de réseau avec un numéro d'ordinateur de 0 désigne l'ensemble du réseau, et un avec le numéro le plus élevé possible (255 pour le réseau C) est utilisé pour message diffusé envoyé à tous les ordinateurs du réseau. Il est plus pratique pour les utilisateurs de ne pas travailler avec des adresses physiques, mais avec noms de domaine réseaux et ordinateurs sur Internet. Un tel nom est composé de symboles séparés par des points. domaines(du lat. dominium - possession.) - fragments du réseau. De droite à gauche, le plus étendu Sénior domaine (premier ou niveau supérieur), puis les domaines imbriqués inférieurs, et ainsi de suite jusqu'au domaine le plus à gauche correspondant au nœud d'extrémité du réseau. Au début du nom de domaine, le nom du serveur peut être précédé du service Internet dans lequel le nœud de réseau donné fonctionne (par exemple, www. - World Wide Web ou ftp. - service de transfert de fichiers). Souvent, les domaines du troisième niveau et des niveaux inférieurs sont appelés sous-domaines ou sous-domaines. Les domaines de premier niveau sont le plus souvent désignés par deux (pays) ou trois (type d'organisation) lettres. Certains d'entre eux sont donnés dans le tableau. 4. Par exemple, microsoft.com est l'adresse de domaine de Microsoft dans le domaine des serveurs commerciaux, et le domaine cit.sibstrin.ru peut signifier l'adresse du sous-domaine du réseau local du centre informatique cit, qui est un sous-domaine du NGASU réseau (Sibstrin) dans le domaine des serveurs russes ru. La correspondance un à un entre les noms physiques et les noms de domaine est assurée par un Système de noms de domaines Internet - DNS (système de noms de domaine anglais), composé d'ordinateurs qui appellent Serveurs DNS(chaque domaine a son propre serveur DNS). L'utilisateur traite les noms de domaine et le transfert de données entre ordinateurs s'effectue à des adresses physiques, automatiquement déterminées en se référant aux serveurs DNS appropriés. Tableau 4. Certains domaines de premier niveau Au sommet de la hiérarchie des serveurs DNS se trouvent serveurs de la zone racine avec les noms a.root_servers.net, b.root_servers.net, etc., dupliquant les informations les unes des autres. Le serveur local, ayant reçu une requête de la machine cliente pour se connecter à une certaine adresse, la transmet au serveur DNS local, qui va extraire le nom de domaine de la requête et soit trouver l'IP correspondante dans sa base de données, soit contacter l'un des les serveurs de la zone racine. Ce dernier renverra un pointeur vers le serveur DNS du domaine connu de lui, qui comprend l'adresse demandée, et sera complètement éliminé du processus. De telles requêtes imbriquées peuvent être répétées, chaque fois que le serveur DNS local contactera le serveur de noms de niveau inférieur. Ce n'est qu'une fois ce processus en plusieurs étapes terminé que le serveur DNS renverra l'adresse résolue à l'ordinateur qui a fait la demande, et l'utilisateur pourra enfin voir sur son moniteur quel type d'information se trouve à l'adresse qu'il a saisie. Les noms de domaine et les adresses IP physiques sont distribués par l'International Clearinghouse for Domain Names and IP Addresses (ICANN), qui comprend 5 représentants de chaque continent (adresse Internet www.icann.org). Pour accéder à un fichier (programme, document) sur Internet, vous devez spécifier une URL (Uniform Resource Locator) composée de : le nom du protocole utilisé pour accéder au fichier et séparé de la partie suivante par deux-points et deux barres obliques ; nom de domaine informatique, séparé du contenu suivant par une barre oblique ; · le nom complet du fichier sur l'ordinateur (sans préciser le lecteur logique), y compris (éventuellement) le chemin d'accès (la liste des répertoires imbriqués), le nom réel et l'extension du fichier. Seules les lettres latines peuvent être utilisées dans l'URL (les lettres minuscules et majuscules sont considérées comme différentes) sans espaces. Le chemin et le nom du fichier peuvent être manquants, ce qui correspond à l'accès à l'ordinateur (serveur) lui-même. Par exemple, une URL telle que http://www.students.informatika.ru/library/txt/klassika.htm signifie que le fichier klassika avec l'extension htm se trouve dans le sous-répertoire txt du répertoire de la bibliothèque sur le serveur des étudiants du domaine informatika.ru. Ce serveur appartient au service www, et le protocole http est utilisé pour accéder au fichier. L'adresse ftp://ftp.netscape.com/books/history.doc est utilisée lors de la récupération du fichier history.doc situé sur le serveur netscape du domaine Internet commercial à l'aide du protocole de transfert de fichiers ftp (service ftp). Très souvent, vous rencontrerez des URL qui ne contiennent pas le nom du fichier html, cependant, lors de la saisie d'une telle URL, nous arrivons toujours à une page Web spécifique. Cela signifie que le document a un nom par défaut qui peut être attribué lors de l'administration du serveur. Le plus souvent, ce nom est index.html, donc l'URL http://www.host.ru peut signifier exactement la même chose que http://www.host.ru/index.html. Le préfixe de protocole http:// par défaut est également généralement omis de l'URL complète. Pour travailler avec le courrier électronique, vous devez vous inscrire sur l'un des serveurs de messagerie Internet de votre boites aux lettres, qui est attribué adresse e-mail. Une telle adresse se compose du nom de domaine du serveur suivi de connexion(nom de la boîte aux lettres, il est sélectionné par l'utilisateur lors de l'inscription). Les deux parties de l'adresse sont séparées par le symbole @ (lisez "et", en Russie, ils utilisent souvent l'expression d'argot "chien"). Par exemple, [courriel protégé]– boîte aux lettres de l'abonné qui a choisi le nom du directeur sur le serveur contora.ru. Comme indiqué ci-dessus, le service Internet leader et le plus largement utilisé aujourd'hui est le World Wide Web (www), qui a couvert une grande quantité de ressources d'information. Ce système permet de trouver facilement des nouvelles, des documents de référence et normatifs, des livres, des articles, des résumés, des logiciels, des opinions et des conseils d'experts sur presque tous les sujets. Aussi www contient un grand nombre de contenu multimédia tels que des graphiques et des animations, des enregistrements vidéo et audio, des jeux en ligne, etc. Le service www est basé sur la présentation de documents sous la forme hypertexte- un texte qui permet non seulement une lecture séquentielle. L'essentiel est que des éléments hypertextes, tels que des phrases, des mots individuels, des dessins, peuvent renvoyer à d'autres fragments du même texte ou à d'autres documents situés, éventuellement, sur un autre ordinateur sur un autre serveur. L'emplacement physique du serveur adressé par le lien n'a pas d'importance. Liens ( hyperliens, hyperliens) sont généralement étiquetés avec une couleur et une police spécifiques, et naviguent automatiquement lorsque l'on clique sur l'étiquette. Ainsi, diverses informations s'avèrent reliées entre elles par un entrelacement de liens, et le savoir collectif de l'homme introduit dans le système s'apparente dans une certaine mesure à la mémoire individuelle, tissée en un tout unique par des associations et des connexions sémantiques. Le concept de www basé sur des hypertextes a été développé en 1989 par le scientifique anglais Timothy Berners-Lee pour le Laboratoire européen de physique des particules, basé en Suisse et regroupant des physiciens du monde entier. Le concept même d'hypertexte a été proposé par le scientifique américain Theodore Holm Nelson en 1965. Le document présenté sur le WWW s'appelle page Web, et l'ordinateur sur lequel se trouvent ces documents - serveur Web. Les pages Web sont créées à l'aide langage de balisage hypertexte HTML(HyperText Markup Language) ou plus puissant Langage XML(anglais e X tensible M arkup L language est un langage de balisage étendu), il existe d'autres formats de balisage. En règle générale, le format de balisage vous permet de définir des liens hypertexte et l'organisation du texte, y compris les caractères de contrôle - Mots clés(de l'étiquette anglaise - étiquette, étiquette). Le formatage d'une page Web sur un moniteur est déterminé à la fois par des balises de contrôle de mise en page et des paramètres spécifiques de l'ordinateur. Vous pouvez placer des images sur des pages Web dans l'un des trois principaux formats graphiques Web − gif, jpg (jpeg), png, objets multimédia (flash-animation, fichiers son et vidéo), formes pour le dialogue avec l'utilisateur, les commandes ( ActiveX) qui exécutent des programmes. Ces programmes sont le plus souvent écrits dans un langage de programmation. Java (Java), conçu pour prendre en charge les pages Web. Les traducteurs de cette langue sont des interprètes, ce qui vous permet d'écrire des programmes universels qui s'exécutent sur différents ordinateurs et dans différents systèmes d'exploitation. Utilisé pour accéder aux pages Web Protocole de transfert hypertexte HTTP(Protocole de transfert hypertexte). Parcourir des pages Web et se déplacer entre elles dans l'espace d'information du réseau à l'aide d'hyperliens ( navigation internet) offrent des programmes spéciaux Navigateurs Web ("navigateurs", le nom le plus courant - navigateurs, de l'anglais. parcourir - regarder, faire défiler). Les navigateurs sont les principaux programmes- clients services www. Actuellement, les navigateurs les plus couramment utilisés sont Mozilla Firefox, Opera, Google Chrome (de Google), Safari, Internet Explorer (de Microsoft). Dans un passé récent, il n'y avait que deux navigateurs populaires - Internet Explorer et Netscape Navigator (une société Netscape). Les navigateurs ont évolué régulièrement depuis l'aube du WWW, devenant un programme de plus en plus important sur l'ordinateur personnel typique. Un navigateur moderne est une application complexe à la fois pour traiter et afficher les différents composants d'une page web et pour assurer une interface entre un site web et ses visiteurs. Presque tous les navigateurs populaires sont distribués gratuitement ou associés à d'autres applications, par exemple, le navigateur Internet Explorer fait partie du système d'exploitation Windows, les derniers navigateurs Mozilla Firefox et Opera sont des programmes gratuits, le navigateur Safari est distribué dans le cadre du Système d'exploitation MacOS. La gestion de tout navigateur moderne est assez standardisée. Au minimum, les outils suivants sont requis pour un travail confortable dans le navigateur : · barre d'adresse(barre d'adresse, barre de navigation, barre d'outils) contient et vous permet de saisir l'URL de la page souhaitée ou le chemin d'accès à un document localisé localement, et place également des boutons de navigation de page standard (Suivant, Précédent, Actualiser, Arrêter, "Accueil") . Dans certains navigateurs, les boutons standard sont placés sur une barre d'outils distincte ; · barre d'état (ligne d'état) est le champ d'information inférieur de la fenêtre du navigateur contenant des informations supplémentaires importantes. Ainsi, lors du chargement d'une page Web, la barre d'état affiche des informations sur sa progression, et lorsque vous passez le curseur de la souris sur un lien, la barre d'état affiche l'URL correspondant au lien ; · barre d'onglets(parfois la barre de favoris, la barre d'onglets) - vous permet d'ouvrir des pages Web supplémentaires dans la fenêtre actuelle et de basculer entre elles. Le concept d'onglets permet, sans renoncer à la possibilité d'ouvrir un lien dans une nouvelle fenêtre de navigateur, de gérer plus facilement des ensembles de pages Web ouvertes simultanément. Ces barres d'outils sont généralement activées par défaut et peuvent être contrôlées à partir du menu Affichage du navigateur. En règle générale, à l'exception des préférences personnelles, les internautes travaillent le plus souvent avec des sites moteurs de recherche. Leur utilisation est très simple - les moteurs de recherche Web renvoient une collection de tous les documents www connus d'eux contenant les mots-clés de la requête faite par l'utilisateur, tandis que la requête est faite en langage naturel. Le plus connu et le plus efficace en runette(segment russophone de l'Internet) moteurs de recherche - Google, Yandex et Mail.Ru. La vitesse de recherche d'informations dans de tels systèmes est assurée par le travail de programmes spéciaux («robots de recherche») invisibles pour l'utilisateur, scannant en permanence divers sites Web et mettant à jour les listes de termes qui s'y trouvent ( index des moteurs de recherche). Ainsi, en réalité, la recherche ne s'effectue pas sur "tous les serveurs Internet", ce qui serait techniquement irréalisable, mais sur la base de données du moteur de recherche, et le manque d'informations adéquates trouvées sur la requête ne signifie pas qu'elle n'est pas sur le Web - vous pouvez essayer d'utiliser un autre moteur de recherche ou répertoire de ressources. Les bases de données du serveur de recherche ne sont pas seulement réapprovisionnées automatiquement. Tout moteur de recherche majeur a la capacité d'indexer votre site et de l'ajouter à la base de données. L'avantage du serveur de recherche est la simplicité de son utilisation, l'inconvénient est le faible degré de sélection des documents sur demande. Les moteurs de recherche et les développeurs de sites Web individuels forment également rubricateurs ou catalogues- des structures hiérarchiques de sujets et de concepts, se déplaçant à travers lesquelles l'utilisateur peut trouver les documents ou sites nécessaires. Le réapprovisionnement du catalogue est généralement effectué par les utilisateurs eux-mêmes après vérification des données saisies par eux par l'administration du serveur. Le catalogue de ressources est toujours mieux ordonné et structuré, mais il faut du temps pour trouver la bonne catégorie, ce qui n'est d'ailleurs pas toujours facile à déterminer. De plus, le volume de l'annuaire est toujours nettement inférieur au nombre de sites indexés par le moteur de recherche. Les sites Web peuvent également être classés en fonction de leur mode de développement. L'expression historique "langage HTML" en russe ne reflète pas le fait que HTML et XML ne sont pas des langages de programmation. Cependant, le plus souvent une page Web moderne - dynamique, c'est-à-dire le résultat du programme serveur qui génère la page en réponse à une requête de l'utilisateur pour une adresse URL particulière (par opposition à statique page dans le balisage HTML stocké sur le serveur sous forme de fichier avec une extension .htm ou .html). Les principaux langages de programmation de serveur sont PHP, Perl, Python et un certain nombre d'autres. Il y a aussi client Langages de programmation Web tels que Javascript et VB Script. Un programme dans un tel langage, inclus dans le texte d'une page Web, est exécuté non pas sur le serveur, mais sur l'ordinateur client, à l'aide d'un interpréteur inclus dans le navigateur de l'utilisateur ou installé séparément. Principales dispositions de la norme internationale ISO/IEC 17799.Partie 19 : Contrôle d'accès. Continuation. Contrôle d'accès au réseauL'accès aux services de réseau internes et externes doit être contrôlé. Cela aidera à garantir que les utilisateurs qui accèdent au réseau et aux services réseau ne violent pas la sécurité de ces services. Pour cela, les moyens suivants sont utilisés : des interfaces appropriées entre le réseau de l'organisation et les réseaux publics et les réseaux appartenant à d'autres organisations ; des mécanismes d'authentification appropriés pour les utilisateurs et les équipements ; contrôle de l'accès des utilisateurs aux services d'information. Politique des services réseauLes connexions non sécurisées aux services réseau peuvent affecter la sécurité de toute une organisation. Les utilisateurs doivent se voir accorder un accès direct uniquement aux services pour lesquels ils ont reçu une autorisation spéciale. Ceci est particulièrement important pour les connexions réseau aux applications sensibles ou critiques pour l'entreprise, ainsi que pour les utilisateurs travaillant dans des zones à haut risque, telles que les lieux publics et les zones extérieures qui ne sont pas couvertes par les protections mises en œuvre dans l'organisation. Une politique devrait être élaborée concernant l'utilisation des réseaux et des services de réseau. Cette politique devrait couvrir : réseaux et services de réseau auxquels l'accès est autorisé ; règles administratives et moyens de protection de l'accès aux connexions réseau et aux services réseau. Cette politique doit être cohérente avec la politique de contrôle d'accès de l'organisation. Authentification des utilisateurs pour les connexions externesLes connexions externes (telles que les connexions commutées) offrent une opportunité potentielle d'accès non autorisé aux informations de l'organisation. Par conséquent, l'authentification doit être utilisée pour l'accès des utilisateurs distants. Il existe différentes méthodes d'authentification. Certaines de ces méthodes offrent une sécurité plus efficace que d'autres - par exemple, les méthodes basées sur le cryptage peuvent fournir une authentification forte. Le niveau de protection requis doit être déterminé dans l'évaluation des risques. Ces informations seront nécessaires lors du choix d'une méthode d'authentification appropriée. Pour authentifier les utilisateurs distants, par exemple, des méthodes cryptographiques, du matériel ou des protocoles de défi et d'accusé de réception peuvent être utilisés. De plus, des lignes privées louées ou des moyens de vérification des adresses réseau des utilisateurs peuvent être utilisés pour garantir l'authenticité de l'origine de la connexion. Les organisations peuvent utiliser des outils de rappel, tels que des modems de rappel, pour se protéger contre les connexions non autorisées et indésirables aux installations de traitement de l'information. Cette méthode de contrôle est utilisée pour authentifier les utilisateurs tentant de se connecter au réseau de l'organisation à partir d'un emplacement distant. Lorsque vous utilisez cette méthode, n'utilisez pas les services réseau qui fournissent le renvoi d'appel. Si le transfert d'appel est toujours disponible, il doit être désactivé pour éviter les vulnérabilités qui lui sont associées. De plus, le processus de rappel doit nécessairement inclure la vérification de la fin effective de la connexion par l'organisation. Sinon, l'utilisateur distant peut rester en ligne en simulant un test de rappel. Les rappels doivent être soigneusement vérifiés pour cette possibilité. Authentification de nœudLes outils de connexion automatique à un ordinateur distant peuvent être utilisés par des attaquants pour obtenir un accès non autorisé à des applications métier. Ainsi, les connexions aux systèmes informatiques distants doivent nécessiter une authentification. Ceci est particulièrement important si la connexion utilise un réseau hors du contrôle de l'organisation. L'authentification de l'hôte peut servir de moyen alternatif pour authentifier des groupes d'utilisateurs distants lors de la connexion à des services informatiques sécurisés partagés. Protection des ports de télédiagnosticL'accès aux ports de diagnostic doit être soigneusement contrôlé. De nombreux ordinateurs et systèmes de communication disposent d'un système de diagnostic à distance connecté via une ligne téléphonique et utilisé par les techniciens de maintenance. S'ils ne sont pas sécurisés, ces ports de diagnostic peuvent être utilisés pour un accès non autorisé. Par conséquent, ils doivent être sécurisés avec un mécanisme de sécurité approprié (comme une serrure). Des règles doivent être mises en place pour s'assurer que ces ports ne sont accessibles qu'après accord entre la personne responsable du système informatique et le technicien de service qui a besoin d'y accéder. Séparation des réseaux informatiquesÀ mesure qu'émergent des partenariats nécessitant l'interconnexion ou le partage de réseaux et d'installations de traitement de l'information, les réseaux dépassent de plus en plus les frontières traditionnelles d'une organisation. Une telle expansion peut augmenter le risque d'accès non autorisé aux systèmes d'information connectés au réseau, dont certains peuvent nécessiter une protection contre d'autres utilisateurs du réseau en raison de leur sensibilité ou de leur confidentialité. Dans ces conditions, il est recommandé d'envisager l'introduction d'outils de contrôle de réseau pour séparer les groupes de services d'information, d'utilisateurs et de systèmes d'information. Une méthode de contrôle de la sécurité dans les grands réseaux consiste à diviser ces réseaux en zones de réseau logiques distinctes, telles que les zones de réseau internes d'une organisation et les zones de réseau externes. Chacune de ces zones est protégée par un certain périmètre de sécurité. Un tel périmètre peut être mis en place en installant une passerelle sécurisée entre les deux réseaux interconnectés pour contrôler l'accès et transférer les informations entre ces deux domaines. Cette passerelle doit être configurée pour filtrer le trafic entre ces domaines et bloquer les accès non autorisés conformément à la politique de contrôle d'accès de l'organisation. Un bon exemple d'une telle passerelle est un système communément appelé pare-feu. conditions d'accès. En outre, l'impact relatif sur les coûts et les performances doit être pris en compte lors de la mise en œuvre du routage réseau et des passerelles. Contrôle de la connexion réseauLes politiques de contrôle d'accès sur les réseaux partagés, en particulier ceux qui s'étendent à l'extérieur de l'organisation, peuvent nécessiter la mise en œuvre de moyens pour restreindre la connectivité des utilisateurs. Des outils similaires peuvent être mis en œuvre à l'aide de passerelles réseau qui filtrent le trafic en fonction d'un tableau ou d'un ensemble de règles donné. Les restrictions introduites doivent être basées sur la politique d'accès et sur les besoins de l'organisation. Ces restrictions doivent être maintenues et mises à jour en temps opportun. Voici des exemples de domaines pour lesquels vous devez introduire des restrictions : E-mail; transfert de fichiers unidirectionnel ; transfert de fichiers bidirectionnel ; accès interactif ; accès au réseau lié à l'heure du jour ou à la date. Contrôle du routage réseauDans les réseaux partagés, en particulier ceux qui s'étendent à l'extérieur de l'organisation, il peut être nécessaire de créer des contrôles de routage pour s'assurer que les connexions informatiques et les flux de données ne violent pas la politique de contrôle d'accès de l'organisation. Un tel contrôle est souvent nécessaire pour les réseaux partagés avec d'autres utilisateurs extérieurs à l'organisation. Les contrôles de routage doivent être basés sur des mécanismes spécifiques de vérification des adresses de source et de destination. De plus, pour isoler les réseaux et empêcher l'apparition de routes entre deux réseaux d'organisations différentes, il est très pratique d'utiliser le mécanisme de traduction d'adresse réseau. Ces outils peuvent être mis en œuvre tant au niveau logiciel que matériel. Lors de la mise en œuvre, il est nécessaire de prendre en compte la puissance des mécanismes sélectionnés. Matériel standard fourni par l'entreprise |


Populaire:
Quel est le meilleur signe du zodiaque !
|
Nouvelle
- Rav, Rabbi, Rabbi - qui est-il ?
- Alexander Prokhanov: biographie, vie personnelle, photos, livres et journalisme
- Politique OSAGO invalide
- Garantie Reso - "réparation en vertu de la nouvelle loi sur la garantie reso et ses conséquences"
- Calcul de l'indemnisation pour OSAGO en cas d'accident - comment vérifier si l'assuré vous trompe ?
- RSA assurant l'assurance du TCP
- Protection enfant prêt immobilier
- Tout sur l'assurance Reso Osago
- Assurance maladie volontaire pour les employés
- Vérification de la police sur la base du PCA