1
/
5
L'importance de la distribution normale dans de nombreux domaines scientifiques (par exemple, les statistiques mathématiques et la physique statistique) découle du théorème central limite de la théorie des probabilités. Si le résultat d'une observation est la somme de nombreuses quantités aléatoires faiblement interdépendantes, dont chacune apporte une petite contribution par rapport à la somme totale, alors à mesure que le nombre de termes augmente, la distribution du résultat centré et normalisé tend à être normale. Cette loi de la théorie des probabilités aboutit à une distribution généralisée de la distribution normale, ce qui explique en partie son nom.
Propriétés
Des moments
Si des variables aléatoires X 1 (\style d'affichage X_(1)) Et X 2 (\style d'affichage X_(2)) sont indépendants et ont une distribution normale avec des attentes mathématiques μ 1 (\displaystyle \mu _(1)) Et μ 2 (\displaystyle \mu _(2)) et les écarts σ 1 2 (\displaystyle \sigma _(1)^(2)) Et σ 2 2 (\displaystyle \sigma _(2)^(2)) en conséquence, alors X 1 + X 2 (\style d'affichage X_(1)+X_(2)) a également une distribution normale avec une espérance mathématique μ 1 + μ 2 (\displaystyle \mu _(1)+\mu _(2)) et écart σ 1 2 + σ 2 2 . (\displaystyle \sigma _(1)^(2)+\sigma _(2)^(2).) Il s’ensuit qu’une variable aléatoire normale peut être représentée comme la somme d’un nombre arbitraire de variables aléatoires normales indépendantes.
Entropie maximale
La distribution normale a l'entropie différentielle maximale parmi toutes les distributions continues dont la variance ne dépasse pas une valeur donnée.
Modélisation de variables pseudo-aléatoires normales
Les méthodes de modélisation approchée les plus simples sont basées sur le théorème central limite. À savoir, si vous ajoutez plusieurs quantités indépendantes distribuées de manière identique avec une variance finie, alors la somme sera distribuée environ Bien. Par exemple, si vous ajoutez 100 indépendants en standard uniformément variables aléatoires distribuées, alors la distribution de la somme sera approximativement normale.
Pour la génération programmatique de variables pseudo-aléatoires normalement distribuées, il est préférable d'utiliser la transformation de Box-Muller. Il vous permet de générer une valeur normalement distribuée basée sur une valeur uniformément distribuée.
Distribution normale dans la nature et les applications
La distribution normale se retrouve souvent dans la nature. Par exemple, les variables aléatoires suivantes sont bien modélisées par la distribution normale :
- déviation lors de la prise de vue.
- erreurs de mesure (cependant, les erreurs de certains instruments de mesure n'ont pas de distribution normale).
- certaines caractéristiques des organismes vivants dans une population.
Cette distribution est si répandue car il s’agit d’une distribution continue infiniment divisible à variance finie. Par conséquent, d'autres l'approchent à la limite, par exemple le binôme et Poisson. Cette distribution modélise de nombreux processus physiques non déterministes.
Relation avec d'autres distributions
- La distribution normale est une distribution Pearson de type XI.
- Le rapport d'une paire de variables aléatoires standard indépendantes normalement distribuées a une distribution de Cauchy. Autrement dit, si la variable aléatoire X (style d'affichage X) représente la relation X = Y / Z (\displaystyle X=Y/Z)(Où Oui (\style d'affichage Y) Et Z (style d'affichage Z)- variables aléatoires normales standard indépendantes), alors il aura une distribution de Cauchy.
- Si z 1 , … , z k (\displaystyle z_(1),\ldots,z_(k))- des variables aléatoires normales standards conjointement indépendantes, c'est-à-dire z je ∼ N (0, 1) (\displaystyle z_(i)\sim N\left(0,1\right)), alors la variable aléatoire x = z 1 2 + … + z k 2 (\displaystyle x=z_(1)^(2)+\ldots +z_(k)^(2)) a une distribution du chi carré avec k degrés de liberté.
- Si la variable aléatoire X (style d'affichage X) est soumis à une distribution lognormale, alors son logarithme népérien a une distribution normale. Autrement dit, si X ∼ L o g N (μ , σ 2) (\displaystyle X\sim \mathrm (LogN) \left(\mu,\sigma ^(2)\right)), Que Y = ln (X) ∼ N (μ , σ 2) (\displaystyle Y=\ln \left(X\right)\sim \mathrm (N) \left(\mu,\sigma ^(2)\right )). Et vice versa, si Oui ∼ N (μ , σ 2) (\displaystyle Y\sim \mathrm (N) \left(\mu,\sigma ^(2)\right)), Que X = exp (Y) ∼ L o g N (μ , σ 2) (\displaystyle X=\exp \left(Y\right)\sim \mathrm (LogN) \left(\mu,\sigma ^(2) \droite)).
- Le rapport des carrés de deux variables aléatoires normales standard a
La loi de distribution normale (souvent appelée loi de Gauss) joue un rôle extrêmement important dans la théorie des probabilités et occupe une position particulière parmi les autres lois de distribution. Il s’agit de la loi de répartition la plus fréquemment rencontrée en pratique. La principale caractéristique qui distingue la loi normale des autres lois est qu'il s'agit d'une loi limitative, à laquelle se rapprochent d'autres lois de distribution dans des conditions typiques très courantes.
On peut prouver que la somme d'un nombre suffisamment grand de variables aléatoires indépendantes (ou faiblement dépendantes), soumises à des lois de distribution (sous réserve de certaines restrictions très lâches), obéit approximativement à la loi normale, et cela se vérifie avec plus de précision, la plus le nombre de variables aléatoires additionnées est grand. La plupart des variables aléatoires rencontrées dans la pratique, comme par exemple les erreurs de mesure, les erreurs de tir, etc., peuvent être représentées comme la somme d'un très grand nombre de termes relativement petits - erreurs élémentaires, dont chacune est provoquée par un cause distincte, indépendante des autres. Quelles que soient les lois de distribution auxquelles sont soumises les erreurs élémentaires individuelles, les caractéristiques de ces distributions dans la somme d'un grand nombre de termes sont nivelées, et la somme s'avère soumise à une loi proche de la normale. La principale limite imposée aux erreurs totalisables est qu’elles jouent toutes un rôle relativement faible dans le total. Si cette condition n'est pas remplie et, par exemple, l'une des erreurs aléatoires s'avère fortement dominante dans son influence sur le montant sur toutes les autres, alors la loi de distribution de cette erreur dominante imposera son influence sur le montant et déterminera son principales caractéristiques du droit de la distribution.
Les théorèmes établissant la loi normale comme limite pour la somme de termes aléatoires indépendants uniformément petits seront discutés plus en détail au chapitre 13.
La loi de distribution normale est caractérisée par une densité de probabilité de la forme :
La courbe de distribution normale a une apparence symétrique en forme de colline (Fig. 6.1.1). L'ordonnée maximale de la courbe, égale à , correspond au point ; À mesure que l'on s'éloigne du point, la densité de distribution diminue, et à , la courbe se rapproche asymptotiquement de l'abscisse.

Découvrons la signification des paramètres numériques et inclus dans l'expression de la loi normale (6.1.1) ; Montrons que la valeur n'est rien de plus qu'une espérance mathématique et que la valeur est l'écart type de la valeur. Pour ce faire, nous calculons les principales caractéristiques numériques de la quantité - espérance mathématique et dispersion.

Utiliser le changement de variable
Il est facile de vérifier que le premier des deux intervalles de la formule (6.1.2) est égal à zéro ; la seconde est la fameuse intégrale d'Euler-Poisson :
 . (6.1.3)
. (6.1.3)
Ainsi,
ceux. le paramètre représente l'espérance mathématique de la valeur. Ce paramètre, notamment dans les problèmes de tir, est souvent appelé centre de dispersion (en abrégé c.r.).
Calculons la variance de la quantité :
 .
.
Appliquer à nouveau le changement de variable
En intégrant par parties, on obtient :
Le premier terme entre accolades est égal à zéro (puisque à diminue plus vite que toute puissance augmente), le deuxième terme selon la formule (6.1.3) est égal à , d'où
Par conséquent, le paramètre de la formule (6.1.1) n’est rien de plus que l’écart type de la valeur.
Découvrons la signification des paramètres et de la distribution normale. Il ressort immédiatement de la formule (6.1.1) que le centre de symétrie de la distribution est le centre de dispersion. Cela ressort clairement du fait que lorsque le signe de la différence est inversé, l’expression (6.1.1) ne change pas. Si vous modifiez le centre de dispersion, la courbe de distribution se déplacera le long de l'axe des abscisses sans changer de forme (Fig. 6.1.2). Le centre de dispersion caractérise la position de la distribution sur l'axe des abscisses.

La dimension du centre de diffusion est la même que la dimension de la variable aléatoire.
Le paramètre caractérise non pas la position, mais la forme même de la courbe de distribution. C'est la caractéristique de la dispersion. La plus grande ordonnée de la courbe de distribution est inversement proportionnelle à : à mesure que vous augmentez, l'ordonnée maximale diminue. Puisque l'aire de la courbe de distribution doit toujours rester égale à l'unité, lorsqu'elle augmente, la courbe de distribution devient plus plate, s'étirant le long de l'axe des x ; au contraire, avec une diminution, la courbe de distribution s'étire vers le haut, se comprimant simultanément sur les côtés, et prend davantage la forme d'une aiguille. En figue. 6.1.3 montre trois courbes normales (I, II, III) en ; parmi celles-ci, la courbe I correspond à la plus grande valeur et la courbe III à la plus petite valeur. Changer le paramètre équivaut à changer l'échelle de la courbe de distribution - augmenter l'échelle le long d'un axe et la même diminuer le long de l'autre.
Des exemples de variables aléatoires distribuées selon la loi normale sont la taille d'une personne et la masse de poissons de la même espèce capturés. La distribution normale signifie ce qui suit
: il existe des valeurs pour la taille humaine, la masse des poissons d'une même espèce, qui sont intuitivement perçues comme « normales » (et en fait moyennes), et dans un échantillon suffisamment grand on les retrouve beaucoup plus souvent que celles qui diffèrent à la hausse ou à la baisse.
La distribution de probabilité normale d'une variable aléatoire continue (parfois une distribution gaussienne) peut être appelée en forme de cloche du fait que la fonction de densité de cette distribution, symétrique par rapport à la moyenne, est très similaire à la coupe d'une cloche (courbe rouge dans la figure ci-dessus).
La probabilité de rencontrer certaines valeurs dans un échantillon est égale à l'aire de la figure sous la courbe, et dans le cas d'une distribution normale on voit que sous le haut de la « cloche », qui correspond aux valeurs tendant vers la moyenne, l'aire, et donc la probabilité, est plus grande que sous les bords. Ainsi, on obtient la même chose qui a déjà été dite : la probabilité de rencontrer une personne de taille « normale » et d'attraper un poisson de poids « normal » est plus élevée que pour des valeurs qui diffèrent à la hausse ou à la baisse. Dans de nombreux cas pratiques, les erreurs de mesure sont réparties selon une loi proche de la normale.
Regardons à nouveau la figure du début de la leçon, qui montre la fonction de densité d'une distribution normale. Le graphique de cette fonction a été obtenu en calculant un certain échantillon de données dans le progiciel STATISTIQUE. Sur celui-ci, les colonnes de l'histogramme représentent des intervalles de valeurs d'échantillon dont la distribution est proche (ou, comme on le dit communément en statistiques, ne diffère pas de manière significative) du graphique réel de la fonction de densité de distribution normale, qui est une courbe rouge. . Le graphique montre que cette courbe est bien en forme de cloche.
La distribution normale est utile à bien des égards, car connaissant uniquement la valeur attendue d'une variable aléatoire continue et son écart type, vous pouvez calculer n'importe quelle probabilité associée à cette variable.
La distribution normale présente également l’avantage d’être l’une des plus simples à utiliser. tests statistiques utilisés pour tester des hypothèses statistiques - Test t de Student- ne peut être utilisé que si les données de l'échantillon obéissent à la loi de distribution normale.
Fonction de densité de la distribution normale d'une variable aléatoire continue peut être trouvé en utilisant la formule :
 ,
,
Où X- valeur de la grandeur changeante, - valeur moyenne, - écart type, e=2,71828... - la base du logarithme népérien, =3,1416...
Propriétés de la fonction de densité de distribution normale

Les changements dans la moyenne déplacent la courbe de fonction de densité normale vers l'axe Bœuf. Si elle augmente, la courbe se déplace vers la droite, si elle diminue, puis vers la gauche.
Si l'écart type change, la hauteur du sommet de la courbe change. Lorsque l’écart type augmente, le haut de la courbe est plus haut et lorsqu’il diminue, il est plus bas.
Probabilité qu'une variable aléatoire normalement distribuée se situe dans un intervalle donné
Déjà dans ce paragraphe, nous commencerons à résoudre des problèmes pratiques dont la signification est indiquée dans le titre. Examinons les possibilités offertes par la théorie pour résoudre les problèmes. Le concept de départ pour calculer la probabilité qu'une variable aléatoire normalement distribuée tombe dans un intervalle donné est la fonction cumulative de la distribution normale.
Fonction de distribution normale cumulative:
 .
.
Cependant, il est problématique d’obtenir des tableaux pour chaque combinaison possible de moyenne et d’écart type. Par conséquent, l’un des moyens simples de calculer la probabilité qu’une variable aléatoire normalement distribuée tombe dans un intervalle donné consiste à utiliser des tables de probabilité pour la distribution normale standardisée.
Une distribution normale est dite standardisée ou normalisée., dont la moyenne est , et l'écart type est .
Fonction de densité de distribution normale normalisée:
 .
.
Fonction cumulative de la distribution normale standardisée:
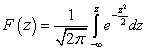 .
.
La figure ci-dessous montre la fonction intégrale de la distribution normale standardisée, dont le graphique a été obtenu en calculant un certain échantillon de données dans le progiciel STATISTIQUE. Le graphique lui-même est une courbe rouge et les valeurs de l'échantillon s'en rapprochent.

Pour agrandir l'image, vous pouvez cliquer dessus avec le bouton gauche de la souris.
Standardiser une variable aléatoire signifie passer des unités d'origine utilisées dans la tâche à des unités standardisées. La normalisation est effectuée selon la formule
En pratique, toutes les valeurs possibles d'une variable aléatoire sont souvent inconnues, de sorte que les valeurs de la moyenne et de l'écart type ne peuvent pas être déterminées avec précision. Ils sont remplacés par la moyenne arithmétique des observations et l'écart type s. Ordre de grandeur z exprime les écarts des valeurs d'une variable aléatoire par rapport à la moyenne arithmétique lors de la mesure des écarts types.
Intervalle ouvert
Le tableau de probabilité pour la distribution normale standardisée, que l'on peut trouver dans presque tous les livres de statistiques, contient les probabilités qu'une variable aléatoire ayant une distribution normale standardisée Z prendra une valeur inférieure à un certain nombre z. Autrement dit, il tombera dans l'intervalle ouvert de moins l'infini à z. Par exemple, la probabilité que la quantité Z inférieur à 1,5, égal à 0,93319.
Exemple 1. L'entreprise produit des pièces dont la durée de vie est normalement répartie avec une moyenne de 1000 heures et un écart type de 200 heures.
Pour une pièce sélectionnée au hasard, calculez la probabilité que sa durée de vie soit d'au moins 900 heures.
Solution. Introduisons la première notation :
La probabilité souhaitée.
Les valeurs des variables aléatoires sont dans un intervalle ouvert. Mais nous savons calculer la probabilité qu'une variable aléatoire prenne une valeur inférieure à une valeur donnée, et selon les conditions du problème, nous devons en trouver une égale ou supérieure à une valeur donnée. C'est l'autre partie de l'espace sous la courbe de densité normale (cloche). Par conséquent, pour trouver la probabilité souhaitée, vous devez soustraire de l'unité la probabilité mentionnée que la variable aléatoire prendra une valeur inférieure aux 900 spécifiés :
Maintenant, la variable aléatoire doit être standardisée.
Nous continuons à introduire la notation :
z = (X ≤ 900)
;
X= 900 - valeur spécifiée de la variable aléatoire ;
μ
= 1000 - valeur moyenne ;
σ
= 200 - écart type.
A partir de ces données, nous obtenons les conditions du problème :
 .
.
Selon les tableaux de variables aléatoires standardisées (limite d'intervalle) z= −0,5 correspond à une probabilité de 0,30854. Soustrayez-le de l'unité et obtenez ce qui est requis dans l'énoncé du problème :
Ainsi, la probabilité que la pièce ait une durée de vie d'au moins 900 heures est de 69 %.
Cette probabilité peut être obtenue à l'aide de la fonction MS Excel NORM.DIST (valeur intégrale - 1) :
P.(X≥900) = 1 - P.(X≤900) = 1 - NORM.DIST(900 ; 1 000 ; 200 ; 1) = 1 - 0,3085 = 0,6915.
À propos des calculs dans MS Excel - dans l'un des paragraphes suivants de cette leçon.
Exemple 2. Dans une certaine ville, le revenu familial annuel moyen est une variable aléatoire normalement distribuée avec une moyenne de 300 000 et un écart type de 50 000. On sait que le revenu de 40 % des familles est inférieur à . UN. Trouver la valeur UN.
Solution. Dans ce problème, 40 % n'est rien de plus que la probabilité qu'une variable aléatoire prenne une valeur dans un intervalle ouvert inférieure à une certaine valeur, indiquée par la lettre UN.
Pour trouver la valeur UN, nous composons d’abord la fonction intégrale :

Selon les conditions du problème
μ
= 300 000 - valeur moyenne ;
σ
= 50 000 - écart type ;
X = UN- la quantité à trouver.
Fabriquer une égalité
 .
.
À partir des tableaux statistiques, nous constatons que la probabilité de 0,40 correspond à la valeur de la limite de l'intervalle z = −0,25
.
Nous créons donc l’égalité

et trouve sa solution :
UN = 287300
.
Réponse : 40 % des familles ont des revenus inférieurs à 287 300.
Intervalle fermé
Dans de nombreux problèmes, il est nécessaire de trouver la probabilité qu'une variable aléatoire normalement distribuée prenne une valeur dans l'intervalle de z 1 à z 2. Autrement dit, il tombera dans un intervalle fermé. Pour résoudre de tels problèmes, il faut retrouver dans le tableau les probabilités correspondant aux limites de l'intervalle, puis trouver la différence entre ces probabilités. Cela nécessite de soustraire la plus petite valeur de la plus grande. Des exemples de solutions à ces problèmes courants sont les suivants. Il vous est demandé de les résoudre vous-même, puis vous pourrez voir les solutions et réponses correctes.
Exemple 3. Le bénéfice d'une entreprise pendant une certaine période est une variable aléatoire soumise à la loi de répartition normale d'une valeur moyenne de 0,5 million. et écart type 0,354. Déterminer, à deux décimales près, la probabilité que le bénéfice de l’entreprise soit compris entre 0,4 et 0,6 m3.
Exemple 4. La longueur de la pièce fabriquée est une variable aléatoire distribuée selon la loi normale avec paramètres μ
=10 et σ
=0,071. Trouvez la probabilité de défauts, avec une précision à deux décimales près, si les dimensions admissibles de la pièce doivent être de 10 ± 0,05.
Astuce : dans ce problème, en plus de trouver la probabilité qu'une variable aléatoire tombe dans un intervalle fermé (la probabilité de recevoir une pièce non défectueuse), vous devez effectuer une action supplémentaire.

permet de déterminer la probabilité que la valeur standardisée Z pas moins -z et pas plus +z, Où z- une valeur arbitrairement choisie d'une variable aléatoire standardisée.
Une méthode approximative pour vérifier la normalité d'une distribution
Une méthode approximative pour vérifier la normalité de la distribution des valeurs des échantillons est basée sur ce qui suit propriété de distribution normale : coefficient d'asymétrie β
1
et coefficient d'aplatissement β
2
sont égaux à zéro.
Coefficient d'asymétrie β
1
caractérise numériquement la symétrie de la distribution empirique par rapport à la moyenne. Si le coefficient d'asymétrie est nul, alors la moyenne arithmétique, la médiane et le mode sont égaux : et la courbe de densité de distribution est symétrique par rapport à la moyenne. Si le coefficient d'asymétrie est inférieur à zéro (β
1
< 0
), alors la moyenne arithmétique est inférieure à la médiane, et la médiane, à son tour, est inférieure à mode () et la courbe est décalée vers la droite (par rapport à la distribution normale). Si le coefficient d'asymétrie est supérieur à zéro (β
1
> 0
), alors la moyenne arithmétique est supérieure à la médiane, et la médiane, à son tour, est supérieure au mode () et la courbe est décalée vers la gauche (par rapport à la distribution normale).
Coefficient d'aplatissement β
2
caractérise la concentration de la distribution empirique autour de la moyenne arithmétique dans la direction de l'axe Oy et le degré de pic de la courbe de densité de distribution. Si le coefficient d'aplatissement est supérieur à zéro, alors la courbe est plus allongée (par rapport à la distribution normale) le long de l'axe Oy(le graphique est plus pointu). Si le coefficient d'aplatissement est inférieur à zéro, alors la courbe est plus aplatie (par rapport à la distribution normale) le long de l'axe Oy(le graphique est plus obtus).
Le coefficient d'asymétrie peut être calculé à l'aide de la fonction MS Excel SKOS. Si vous vérifiez un tableau de données, vous devez alors saisir la plage de données dans une case « Nombre ».

Le coefficient d'aplatissement peut être calculé à l'aide de la fonction MS Excel KURTESS. Lors de la vérification d'un tableau de données, il suffit également de saisir la plage de données dans une case « Nombre ».

Ainsi, comme nous le savons déjà, avec une distribution normale, les coefficients d'asymétrie et d'aplatissement sont égaux à zéro. Mais que se passerait-il si nous obtenions des coefficients d'asymétrie de -0,14, 0,22, 0,43 et des coefficients d'aplatissement de 0,17, -0,31, 0,55 ? La question est tout à fait juste, car dans la pratique, nous n'avons affaire qu'à des valeurs approximatives d'asymétrie et d'aplatissement, qui sont sujettes à une dispersion inévitable et incontrôlée. On ne peut donc pas exiger que ces coefficients soient strictement égaux à zéro ; ils doivent seulement être suffisamment proches de zéro. Mais que signifie assez ?
Il est nécessaire de comparer les valeurs empiriques obtenues avec des valeurs acceptables. Pour ce faire, vous devez vérifier les inégalités suivantes (comparer les valeurs des coefficients de module avec les valeurs critiques - les limites de la zone de test d'hypothèse).
Pour le coefficient d'asymétrie β
1
.
) joue un rôle particulièrement important dans la théorie des probabilités et est le plus souvent utilisé pour résoudre des problèmes pratiques. Sa principale caractéristique est qu'il s'agit d'une loi limitative, à laquelle se rapprochent d'autres lois de distribution dans des conditions typiques très courantes. Par exemple, la somme d'un nombre suffisamment grand de variables aléatoires indépendantes (ou faiblement dépendantes) obéit approximativement à la loi normale, et cela est vrai d'autant plus précisément que les variables aléatoires sont additionnées.
Il a été prouvé expérimentalement que les erreurs de mesure, les écarts dans les dimensions géométriques et la position des éléments de la structure du bâtiment lors de leur fabrication et de leur installation, ainsi que la variabilité des caractéristiques physiques et mécaniques des matériaux et des charges agissant sur les structures du bâtiment sont soumis à la loi normale.
Presque toutes les variables aléatoires sont soumises à la distribution gaussienne, dont l'écart par rapport aux valeurs moyennes est causé par un large ensemble de facteurs aléatoires, chacun étant individuellement insignifiant. (théorème central limite).
Distribution normale est la distribution d'une variable aléatoire continue pour laquelle la densité de probabilité a la forme (Fig. 18.1).
Riz. 18.1. Loi de distribution normale à 1< a 2 .
où a et sont des paramètres de distribution.
Les caractéristiques probabilistes d'une variable aléatoire distribuée selon la loi normale sont égales à :
Espérance mathématique (18.2)
Écart (18,3)
Écart type (18,4)
Coefficient d'asymétrie UNE = 0(18.5)
Excès E= 0. (18.6)
Le paramètre σ inclus dans la distribution gaussienne est égal au rapport quadratique moyen de la variable aléatoire. Ordre de grandeur UN détermine la position du centre de distribution (voir Fig. 18.1) et la valeur UN— largeur de distribution (Fig. 18.2), c'est-à-dire écart statistique autour de la valeur moyenne.
Riz. 18.2. Loi de distribution normale à σ 1< σ 2 < σ 3
La probabilité de tomber dans un intervalle donné (de x 1 à x 2) pour une distribution normale, comme dans tous les cas, est déterminée par l'intégrale de la densité de probabilité (18.1), qui ne s'exprime pas par des fonctions élémentaires et est représentée par une fonction spéciale appelée fonction de Laplace (intégrale de probabilité).
Une des représentations de l'intégrale de probabilité :
Ordre de grandeur Et appelé quantile
On peut voir que Ф(х) est une fonction impaire, c'est-à-dire Ф(-х) = -Ф(х) .
Les valeurs de cette fonction sont calculées et présentées sous forme de tableaux dans la littérature technique et pédagogique.
La fonction de distribution de la loi normale (Fig. 18.3) peut être exprimée par l'intégrale de probabilité :
Riz. 18.2. Fonction de distribution normale.
La probabilité qu'une variable aléatoire distribuée selon une loi normale tombe dans l'intervalle de X.à x, est déterminé par l'expression :
Il convient de noter que
Ф(0) = 0 ; Ф(∞) = 0,5 ; Ф(-∞) = -0,5.
Lors de la résolution de problèmes pratiques liés à la distribution, il est souvent nécessaire de considérer la probabilité de tomber dans un intervalle symétrique par rapport à l'espérance mathématique, si la longueur de cet intervalle, c'est-à-dire si l'intervalle lui-même a une limite de à , nous avons :
Lors de la résolution de problèmes pratiques, les limites des écarts des variables aléatoires sont exprimées par la norme, l'écart type, multiplié par un certain facteur qui détermine les limites de la région des écarts de la variable aléatoire.
En prenant et en utilisant également la formule (18.10) et le tableau Ф(х) (Annexe n°1), on obtient
Ces formules montrent que si une variable aléatoire a une distribution normale, alors la probabilité de son écart par rapport à sa valeur moyenne d'au plus σ est de 68,27 %, d'au plus 2σ est de 95,45 % et d'au plus 3σ - 99,73 %.
Étant donné que la valeur de 0,9973 est proche de l'unité, il est considéré comme pratiquement impossible que la distribution normale d'une variable aléatoire s'écarte de l'espérance mathématique de plus de 3σ. Cette règle, valable uniquement pour la distribution normale, est appelée règle des trois sigma. Sa violation est probable P = 1 - 0,9973 = 0,0027. Cette règle est utilisée lors de l'établissement des limites des écarts admissibles des tolérances des caractéristiques géométriques des produits et des structures.
Aléatoire si, à la suite d'une expérience, il peut prendre des valeurs réelles avec certaines probabilités. La caractéristique la plus complète et la plus complète d'une variable aléatoire est la loi de distribution. La loi de distribution est une fonction (tableau, graphique, formule) qui permet de déterminer la probabilité qu'une variable aléatoire X prenne une certaine valeur xi ou tombe dans un certain intervalle. Si une variable aléatoire a une loi de distribution donnée, alors on dit qu'elle est distribuée selon cette loi ou obéit à cette loi de distribution.
Chaque droit de la distribution est une fonction qui décrit complètement une variable aléatoire d'un point de vue probabiliste. En pratique, la distribution de probabilité d’une variable aléatoire X doit souvent être jugée uniquement à partir des résultats de tests.
Distribution normale
Distribution normale, également appelée distribution gaussienne, est une distribution de probabilité qui joue un rôle essentiel dans de nombreux domaines de la connaissance, notamment en physique. Une grandeur physique suit une distribution normale lorsqu’elle est soumise à l’influence d’un très grand nombre de bruits aléatoires. Il est clair que cette situation est extrêmement courante, on peut donc dire que de toutes les distributions, la distribution normale est la plus courante par nature - d'où l'un de ses noms.
La distribution normale dépend de deux paramètres - le déplacement et l'échelle, c'est-à-dire que d'un point de vue mathématique, il ne s'agit pas d'une distribution, mais de toute une famille d'entre elles. Les valeurs des paramètres correspondent aux valeurs de la moyenne (espérance mathématique) et de l'étalement (écart type).


La distribution normale standard est une distribution normale avec une espérance mathématique de 0 et un écart type de 1.


Coefficient d'asymétrie

Le coefficient d'asymétrie est positif si la queue droite de la distribution est plus longue que la gauche, et négatif dans le cas contraire.
Si la distribution est symétrique par rapport à l'espérance mathématique, alors son coefficient d'asymétrie est nul.

Le coefficient d'asymétrie de l'échantillon est utilisé pour tester la symétrie de la distribution ainsi qu'un test préliminaire approximatif de normalité. Cela permet de rejeter, mais ne permet pas d’accepter, l’hypothèse de normalité.
Coefficient d'aplatissement

Le coefficient d'aplatissement (coefficient de pic) est une mesure de la netteté du pic de la distribution d'une variable aléatoire.
«Moins trois» à la fin de la formule est introduit de sorte que le coefficient d'aplatissement de la distribution normale soit égal à zéro. Il est positif si le pic de la distribution autour de l’espérance mathématique est net, et négatif s’il est lisse.

Moments d'une variable aléatoire
Le moment d'une variable aléatoire est une caractéristique numérique de la distribution d'une variable aléatoire donnée.






